Projects
Army ANT⌗
Army ANT is an information retrieval research framework that supports experimentation with classical approaches, while also providing a high-level abstraction that motivates the implementation of innovative approaches in a shared evaluation environment. It facilitates the use of combined data, and it provides an environment for testing and evaluating multiple retrieval tasks, supporting keyword or entity queries, as well as documents, entities, or even terms, as the rankable results.
This software contains the majority of the code I developed throughout my PhD, providing iterators for well-known test collection, as well as evaluators for several common retrieval tasks from the TREC and INEX evaluation forums. Several experimental search models are also available in Army ANT, along with classical approaches based on Apache Lucene.
The code is available at https://github.com/feup-infolab/army-ant, and several Docker images are also available at https://hub.docker.com/r/jldevezas/army-ant, which can be installed using Docker Compose based on the code at https://github.com/feup-infolab/army-ant-install.
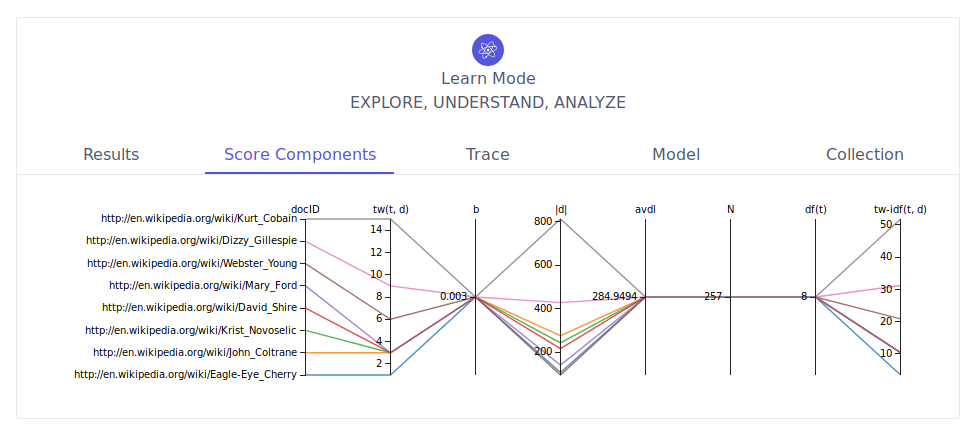
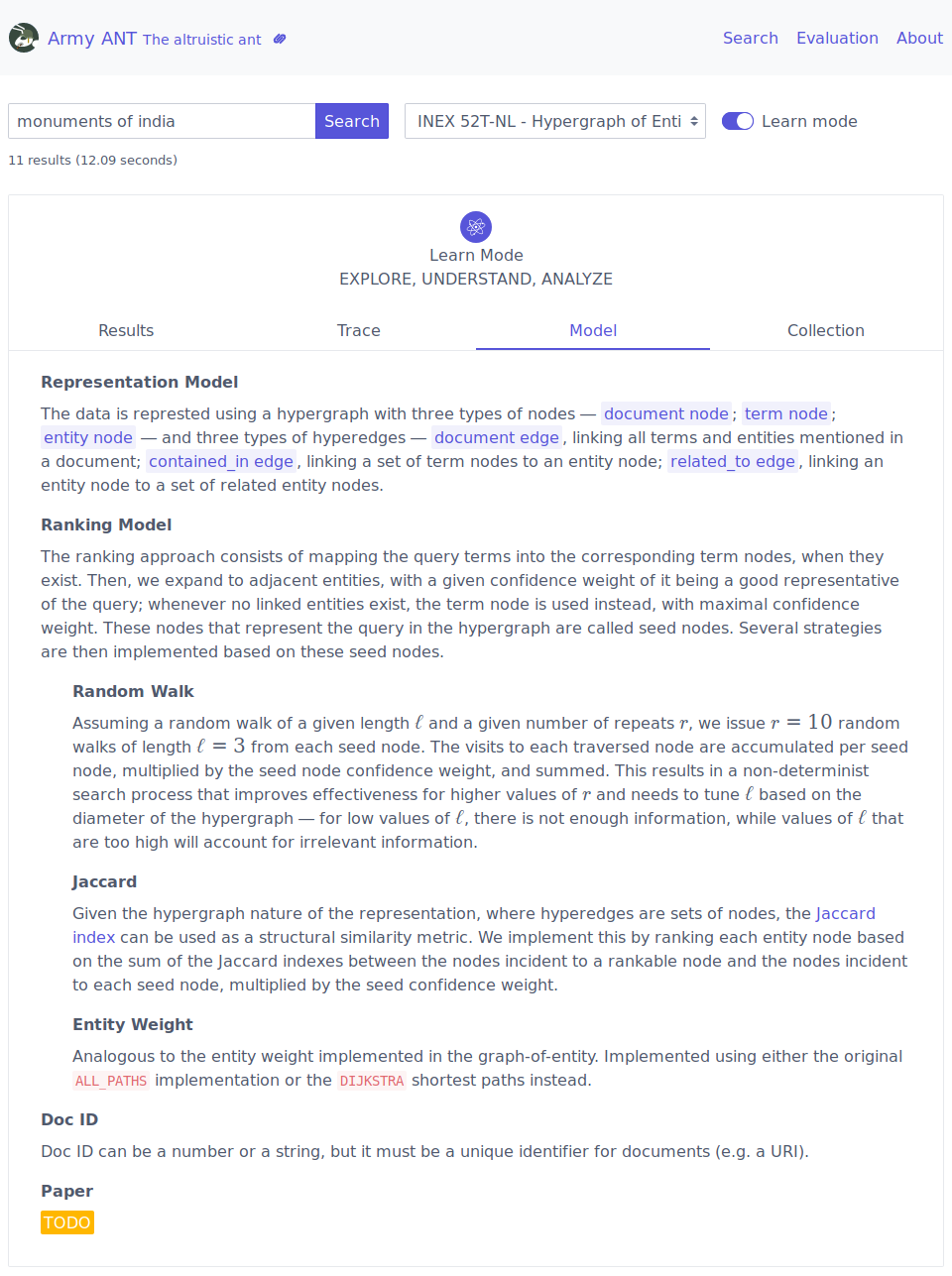
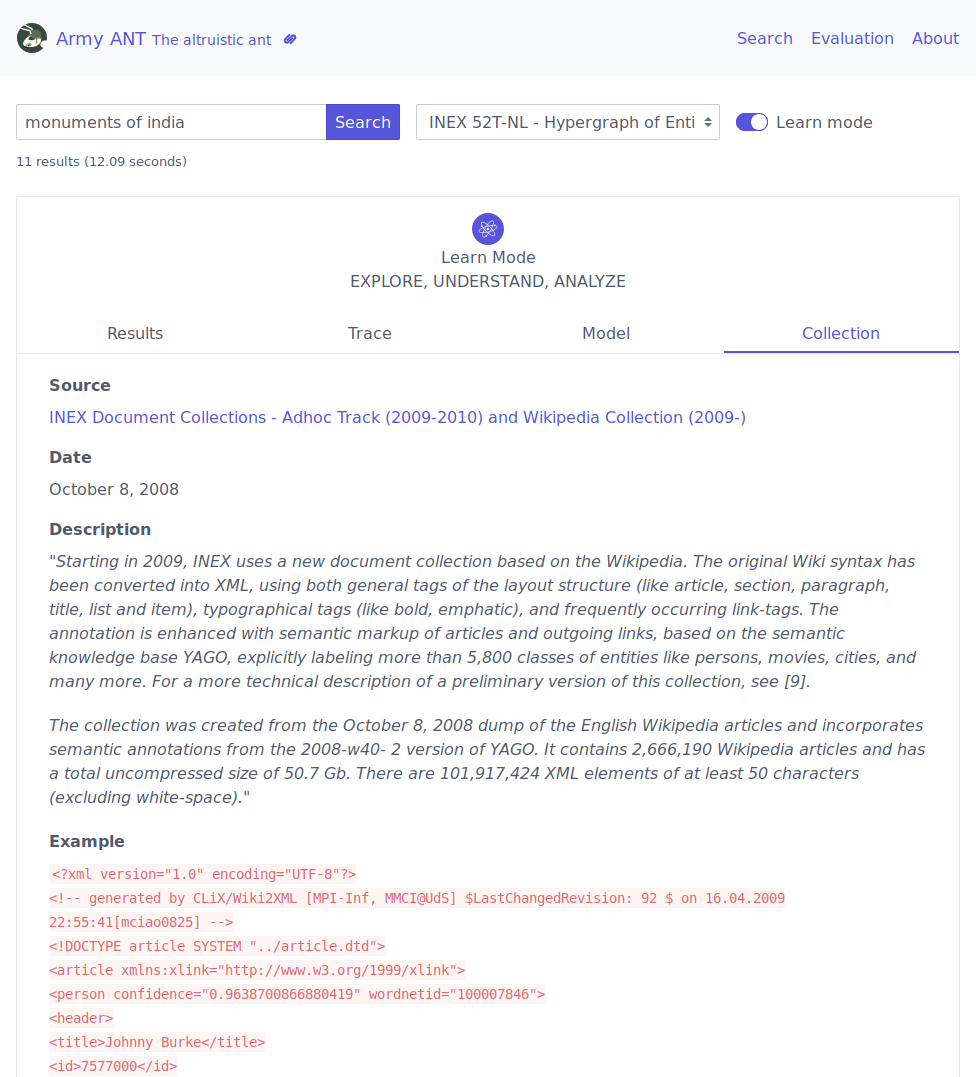
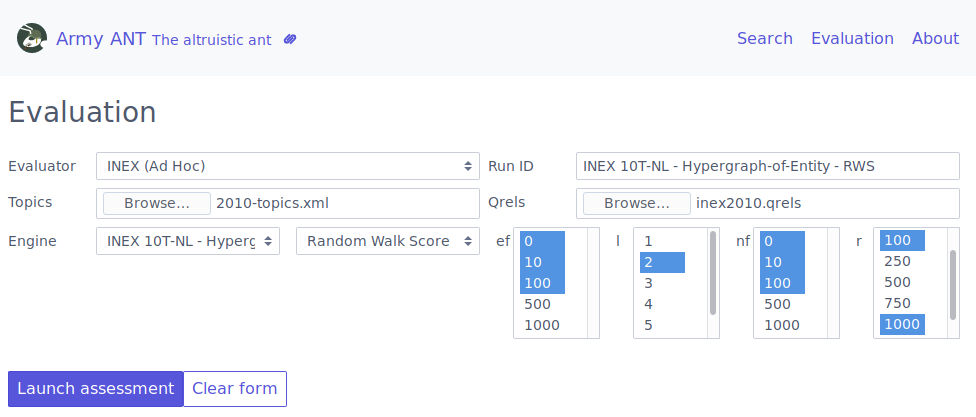
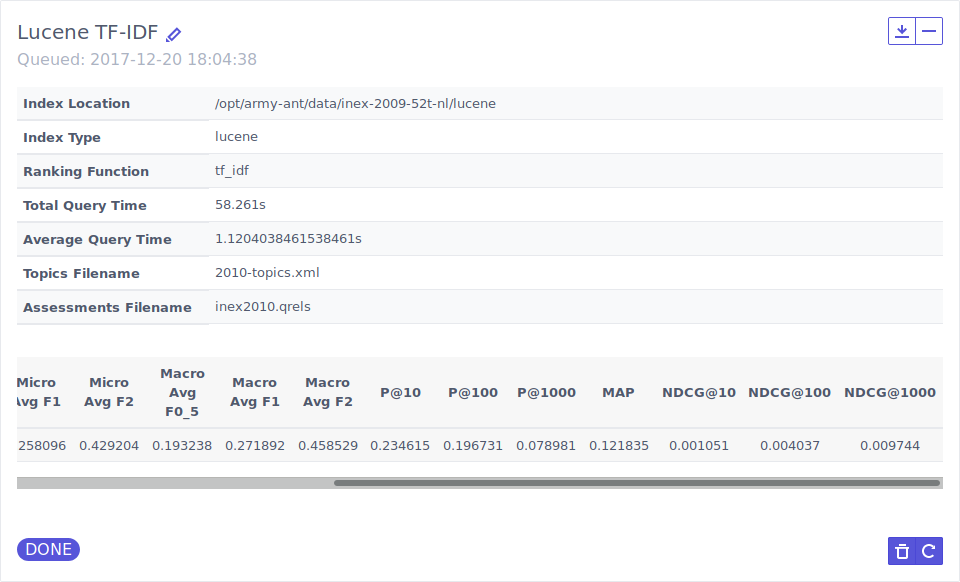
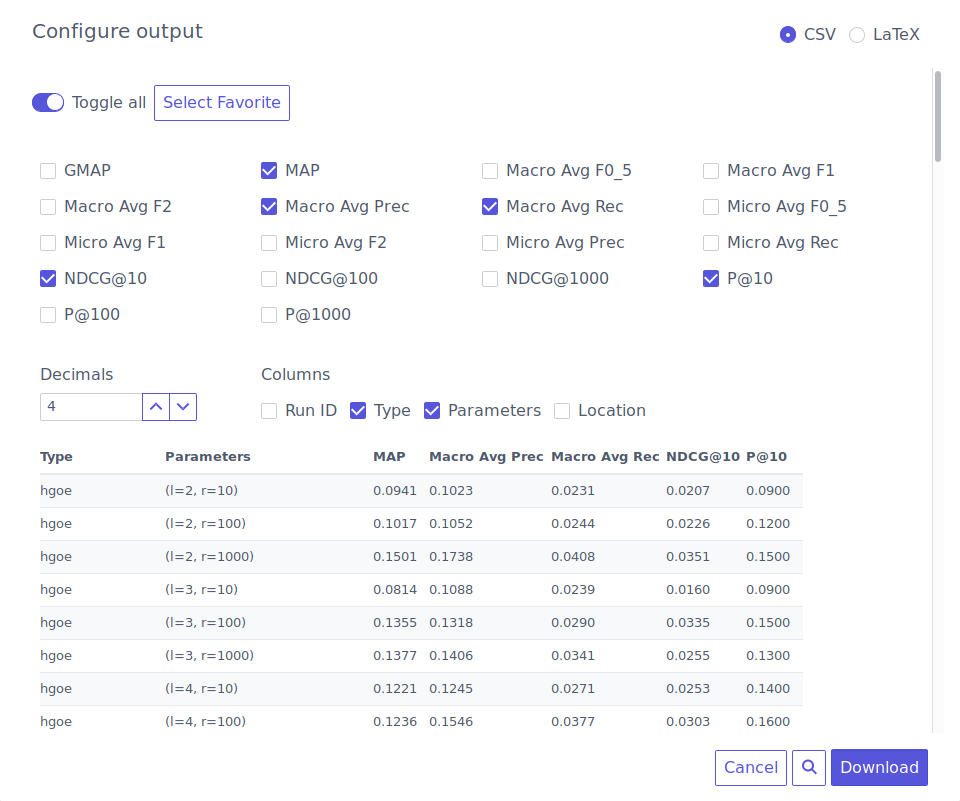
FeedArchive⌗
FeedArchive was a FourEyes prototype developed at FEUP InfoLab, under INESC TEC’s TEC4MEDIA innovation branch. The developed prototype provides a convenient web interface to manage web page archival based on available RSS or Atom feeds.
Periodical crawls for configured sources are scheduled via crontab. The system then collects metadata from RSS or Atom and retrieves all webpage resources, rewriting links to point to the local copies.
In the code, archival can be implemented based on one of two approaches, which differ in their way of organizing collected files. The default approach creates individual folders per webpage, containing all the required resources (ready for download), while a secondary approach is focused on managing storage space more efficiently, relying on a directory tree of content-based hashes that work as a unique identifier for shared content.
The following demo video illustrates the setup and usage workflow for FeedArchive.
ANT⌗
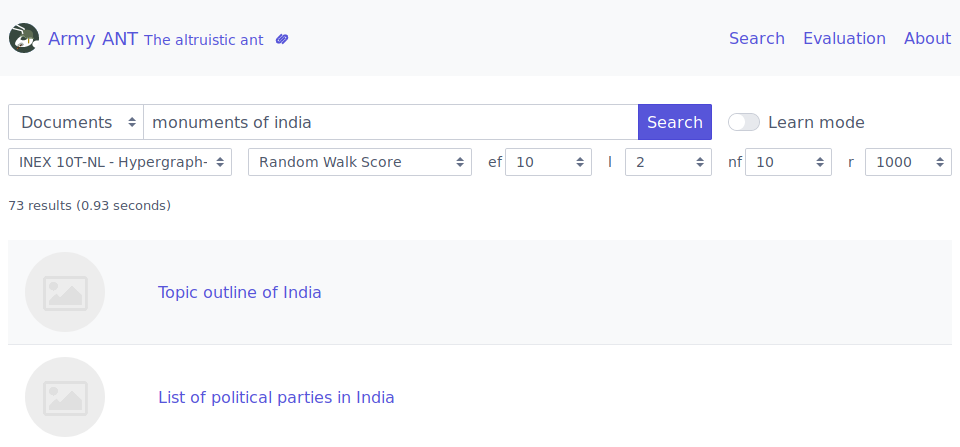
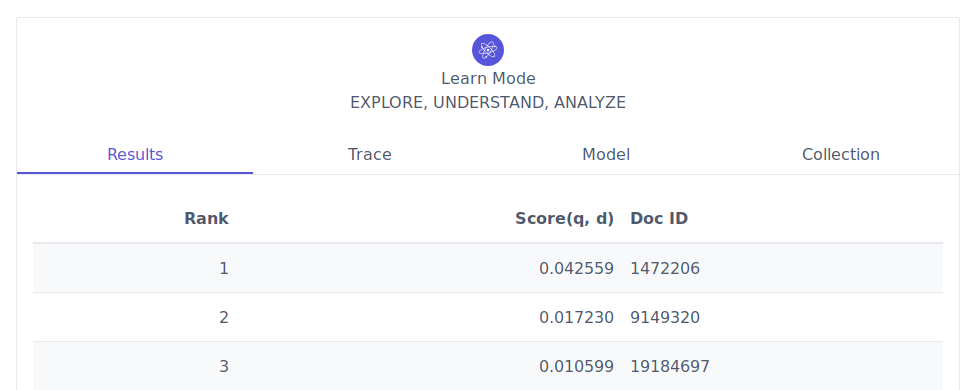
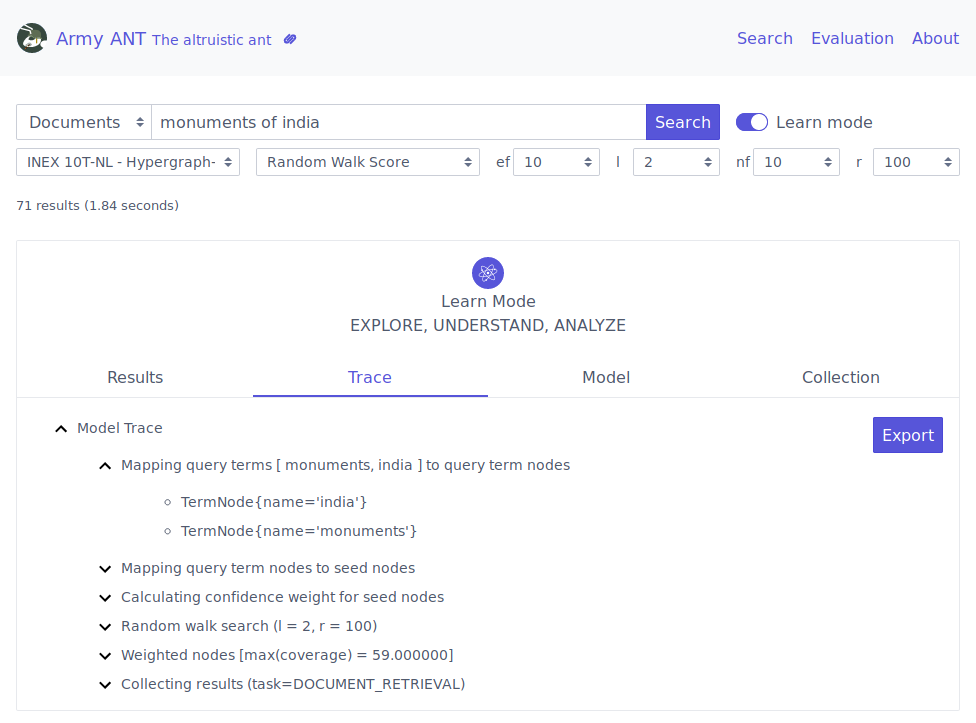
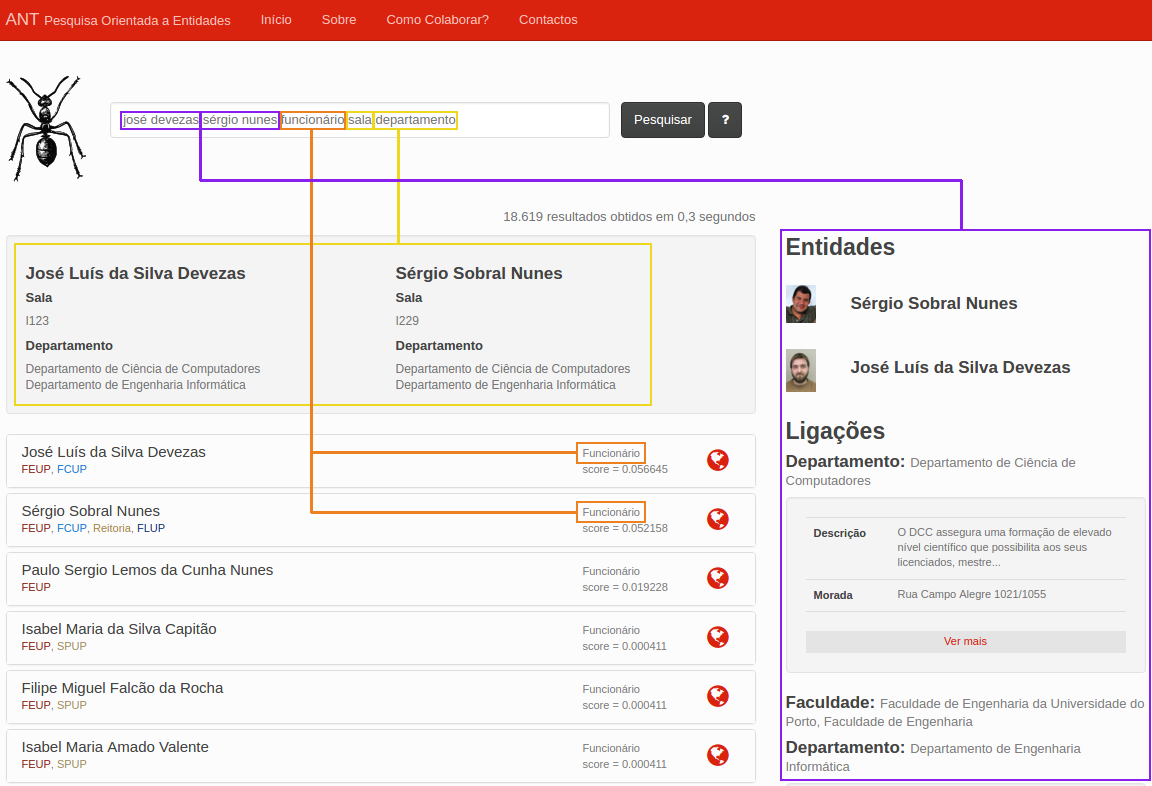
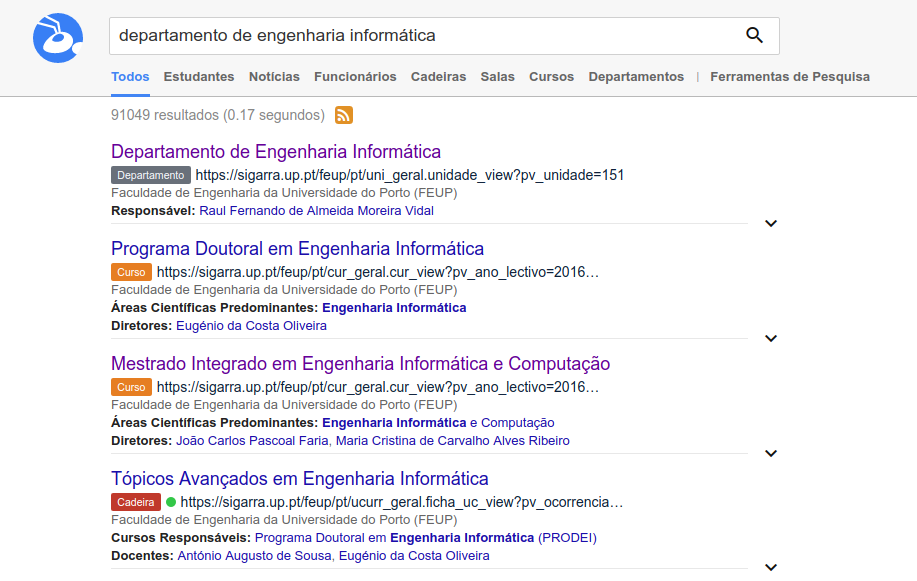
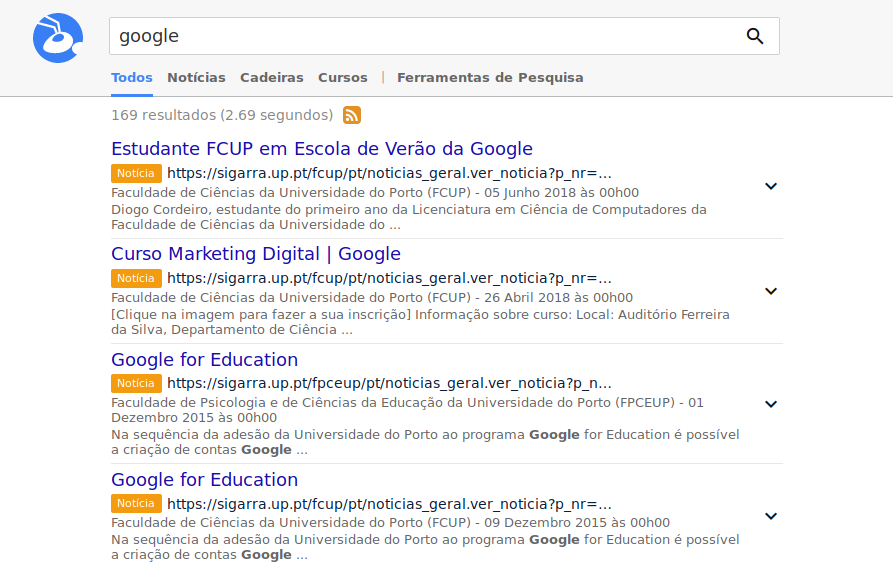
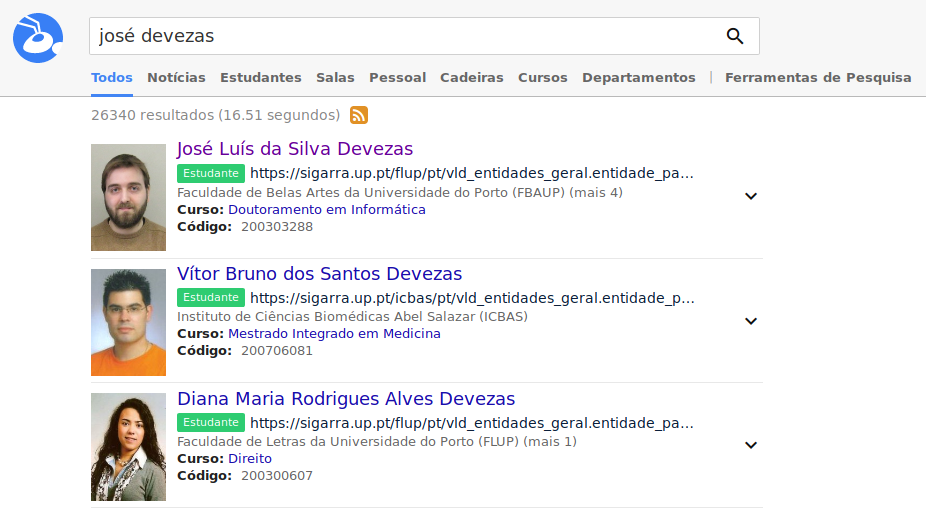
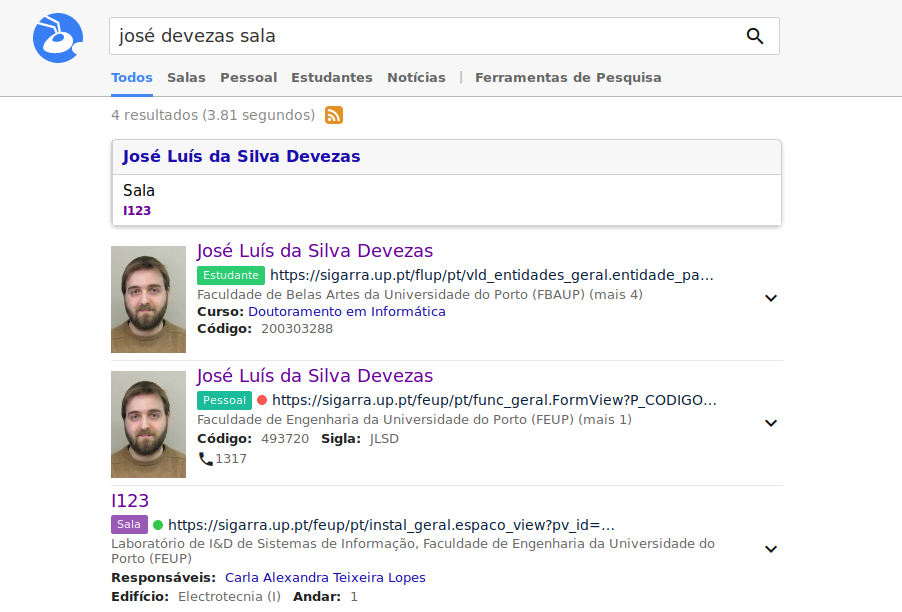
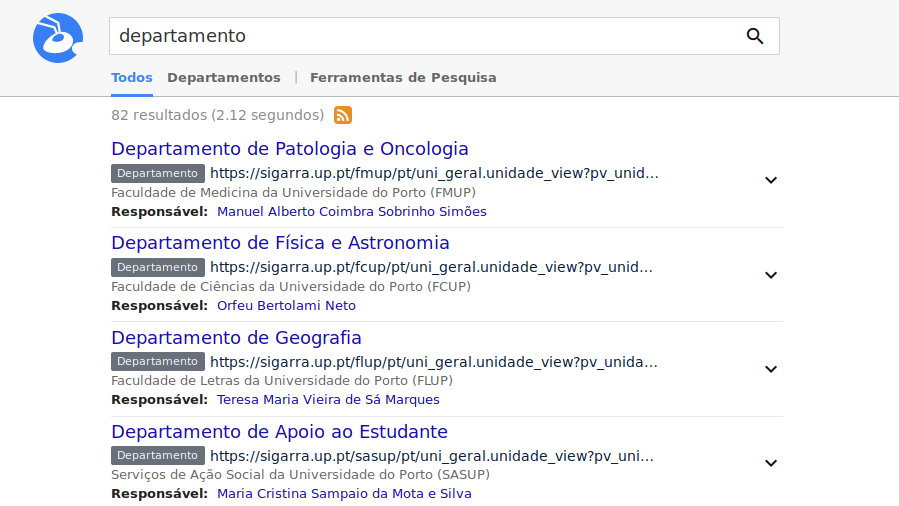
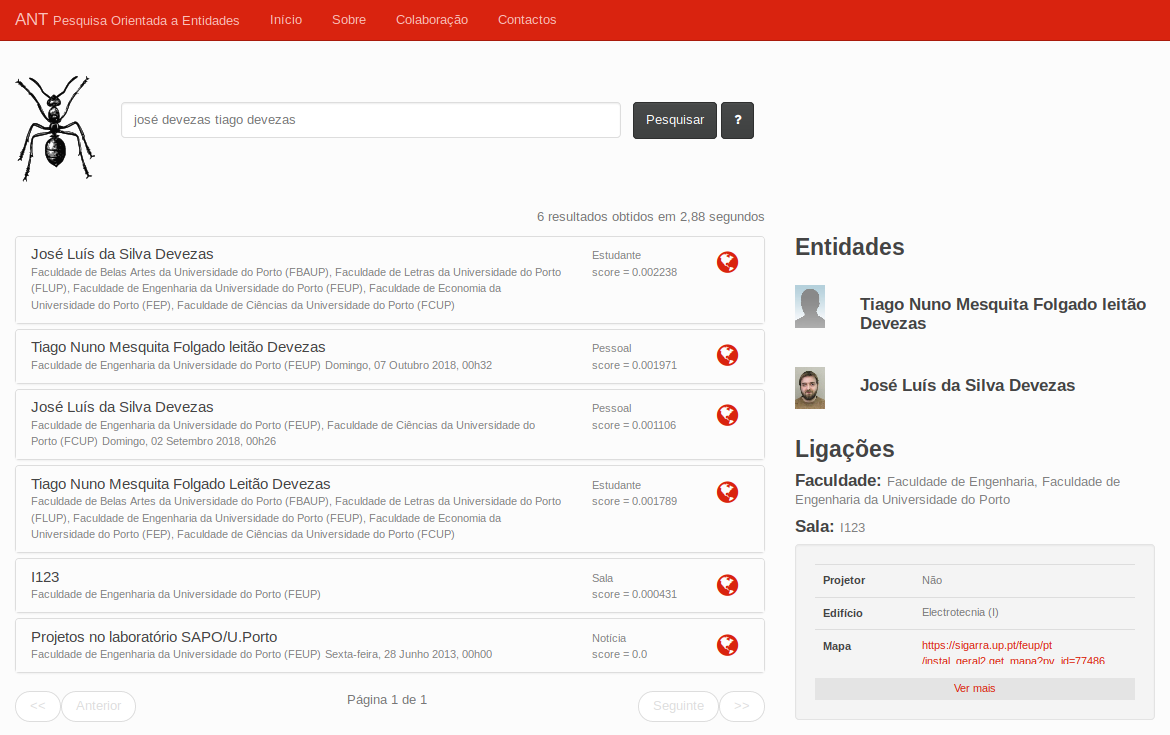
ANT is an entity-oriented search engine available at http://ant.fe.up.pt, that indexes data from the SIGARRA Information System. On one side, it aims at improving search in U.Porto. On the other side, it aims at providing a platform to educate students and to support future research in the area.
This research project motivated my doctoral proposal, providing the ideal platform for the integration of previous areas of interest, particularly information retrieval and network science, but also recommendation and personalization. Working in ANT led me to identify several challenges in the area of entity-oriented search and to devise an innovative and focused contribution.
In a similar fashion to Google and other modern search engines, this enabled our system to answer user questions more directly, well beyond the traditional keyword-based matching. This integrated solution, which includes the segmentation and annotation of queries, is illustrated in the following figures. Please notice that a team of people was involved in the development of ANT. You can find them here.
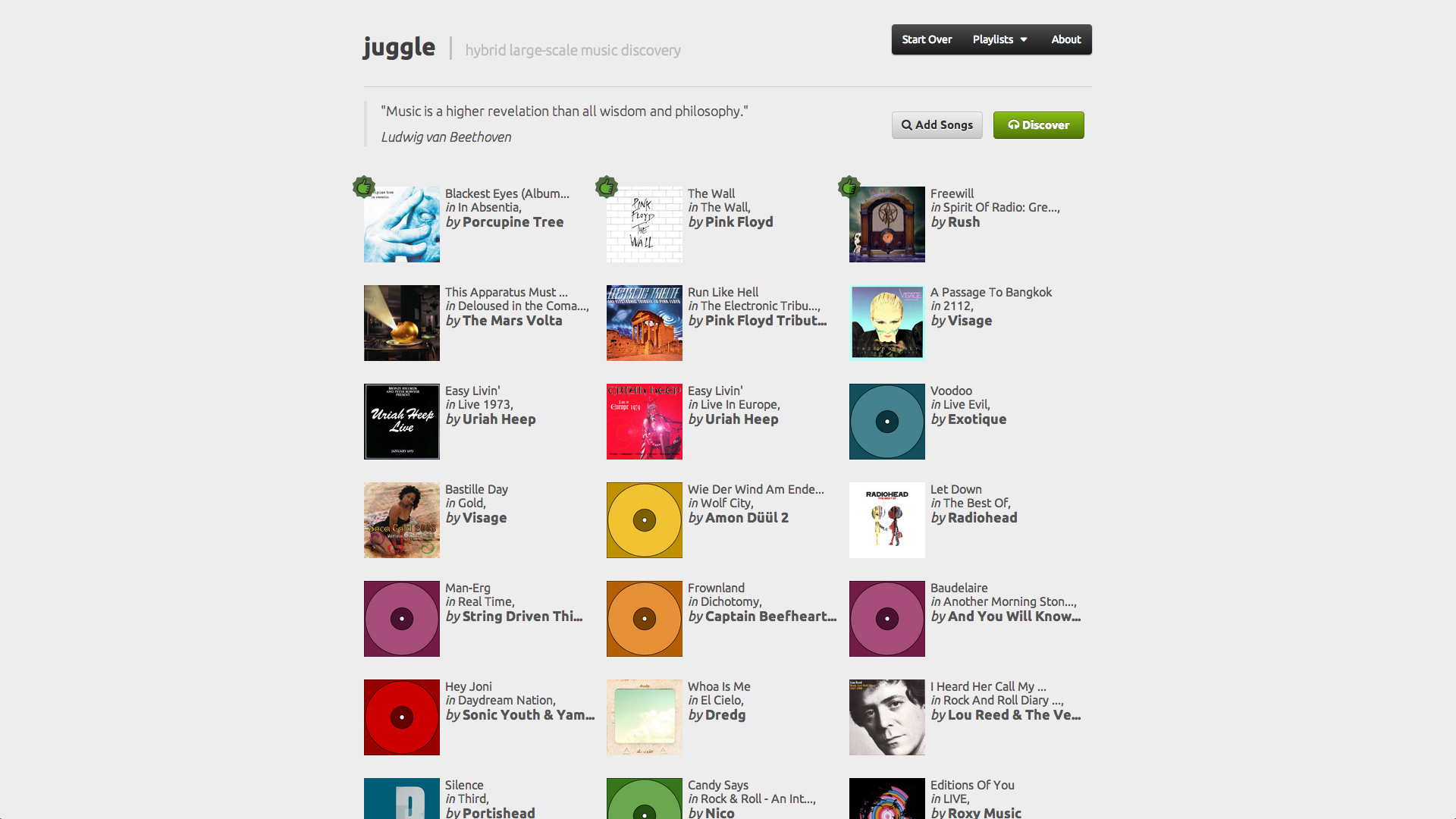
Juggle⌗
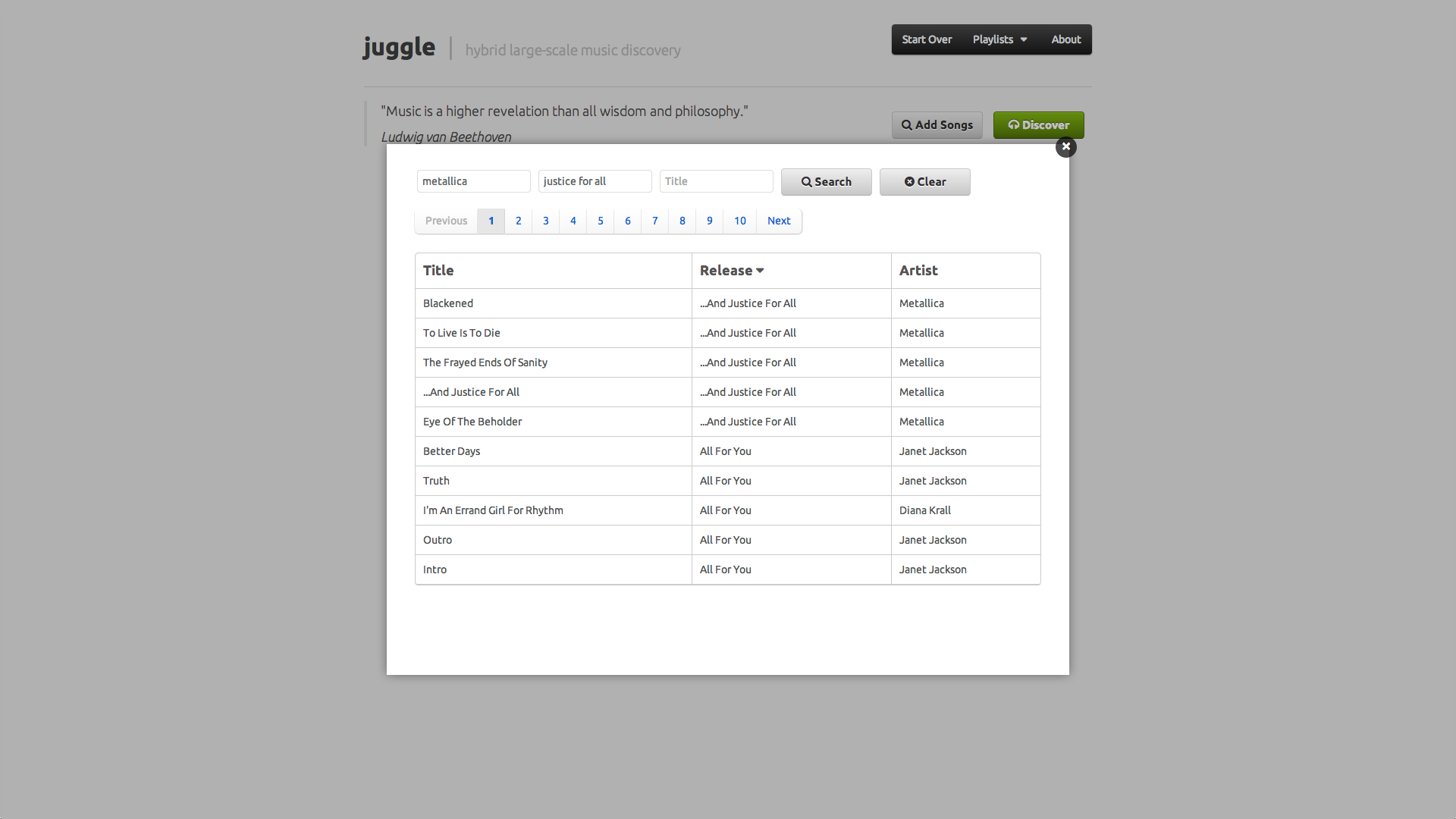
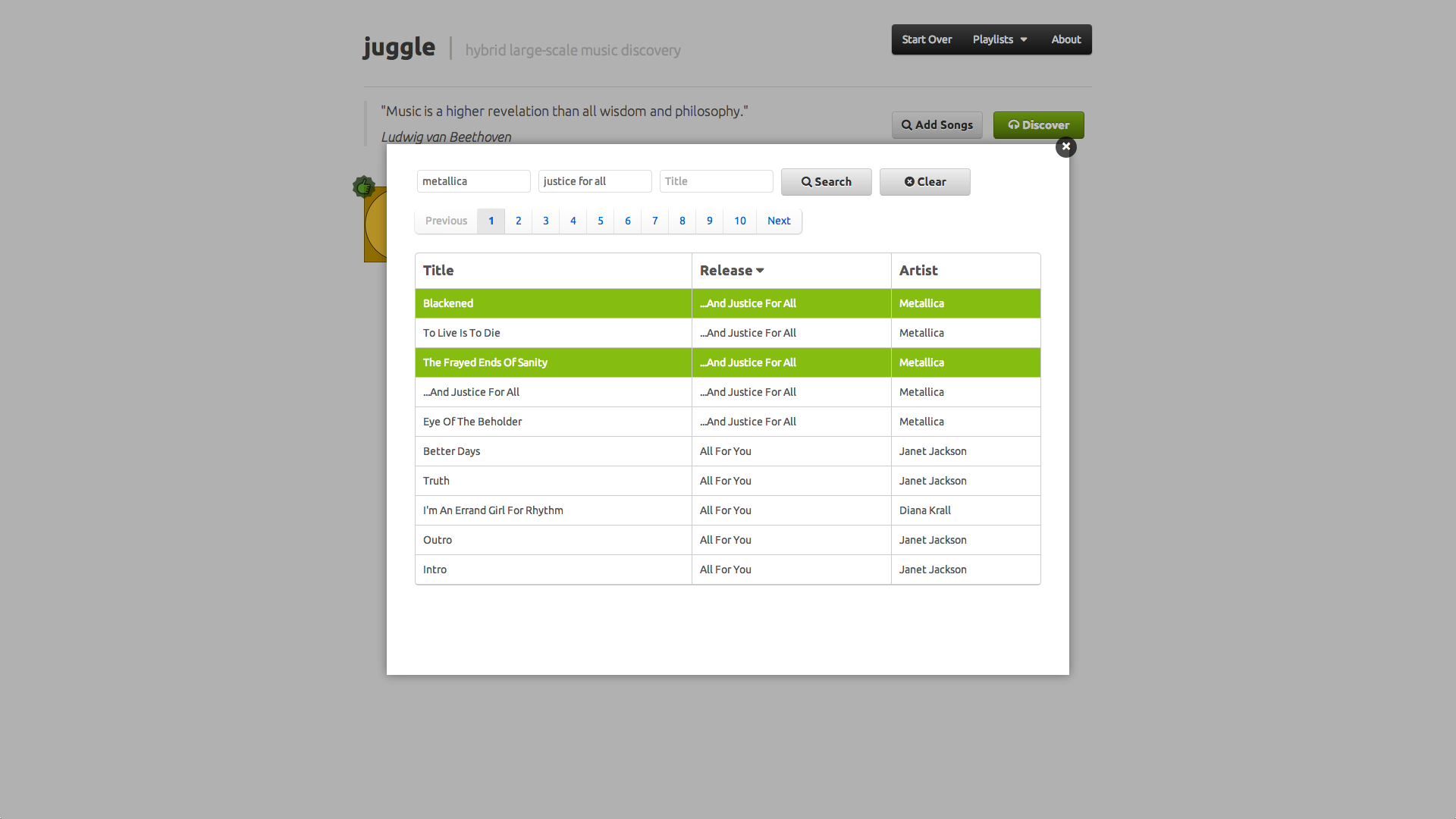
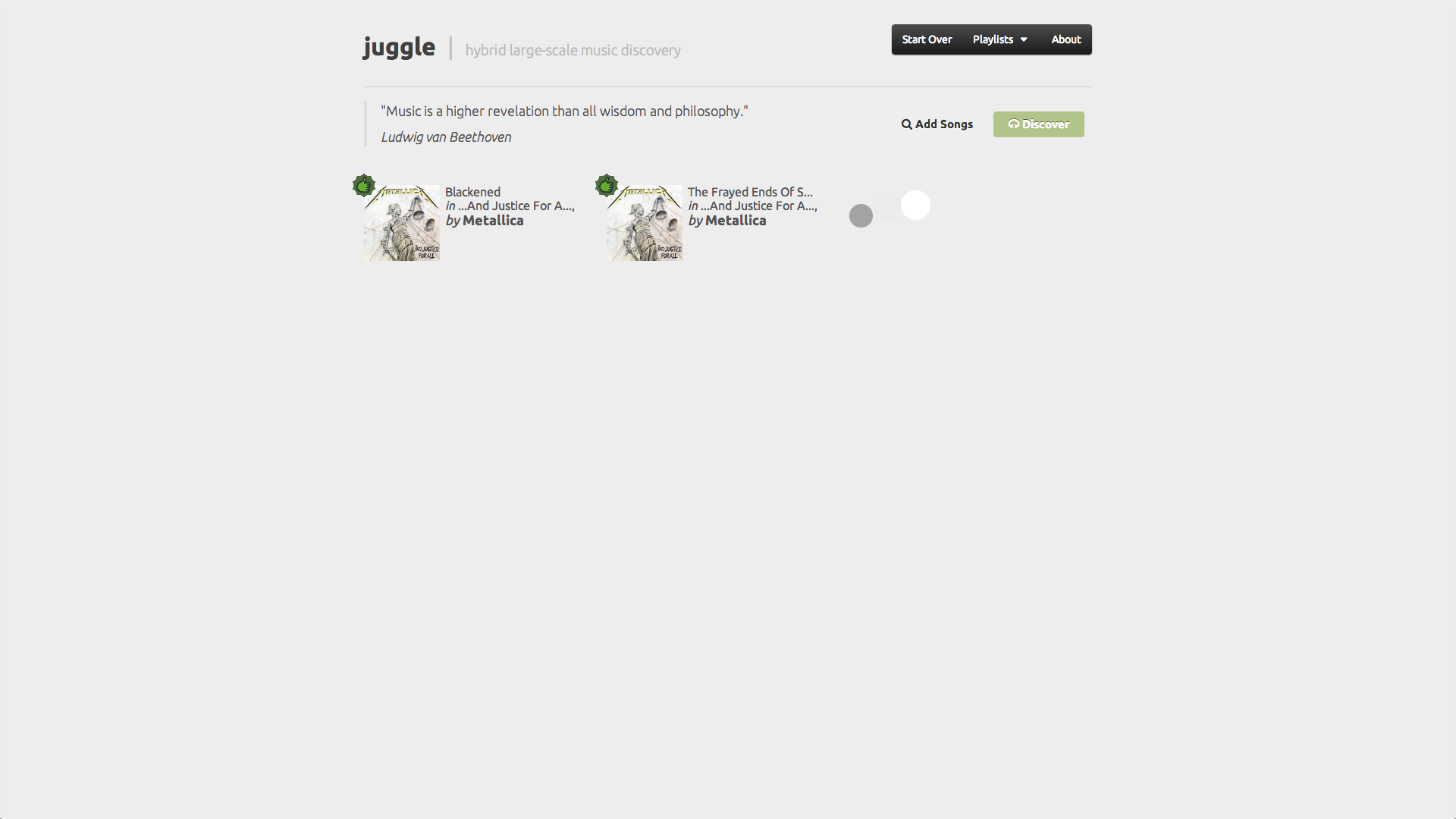
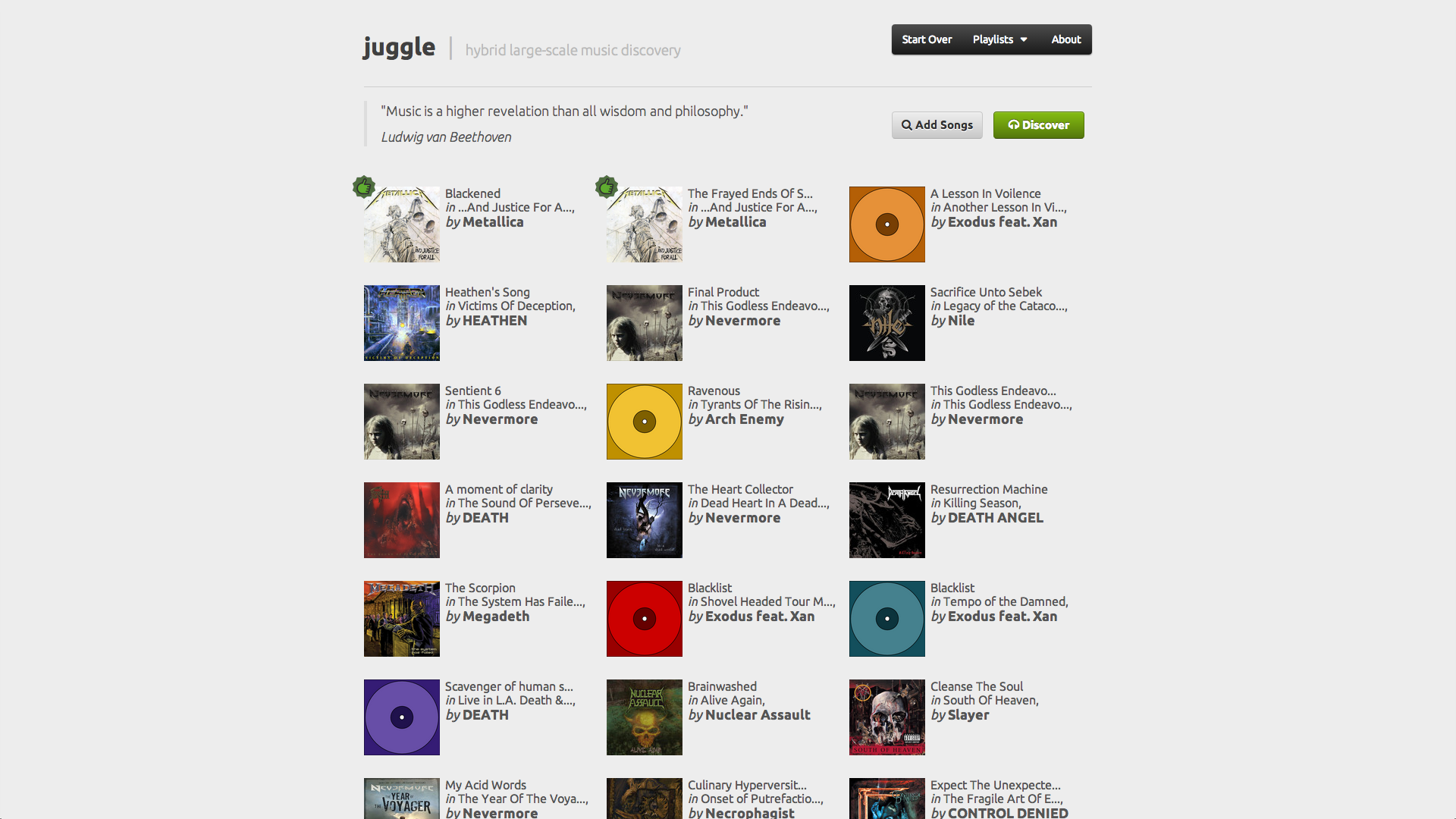
Juggle project aimed at improving music discovery based on a hybrid large-scale recommender system, capable of handling and combining different types of data, namely text and audio content, context from elements such as tags or location, and collaborative information from user profiles.
We tackled the challenges of multimodality and large-scale by developing a graph-based recommender system, supported on Neo4j, a popular and robust graph database that facilitated the modeling of content, context and collaborative information as nodes and edges in a graph. One of the biggest challenges was the translation of audio content to relationships in a graph, specifically the comparison of the audio features of a million songs with each other, which we solved by using an approximate search algorithm from image retrieval.
Our recommendation algorithm was mainly supported on neighborhood methods for collaborative filtering, but we also used metrics from text retrieval to boost the relevance of tags in the long tail, while not completely disregarding tag popularity, in order to offer a playlist that better potentiated the discovery of music.
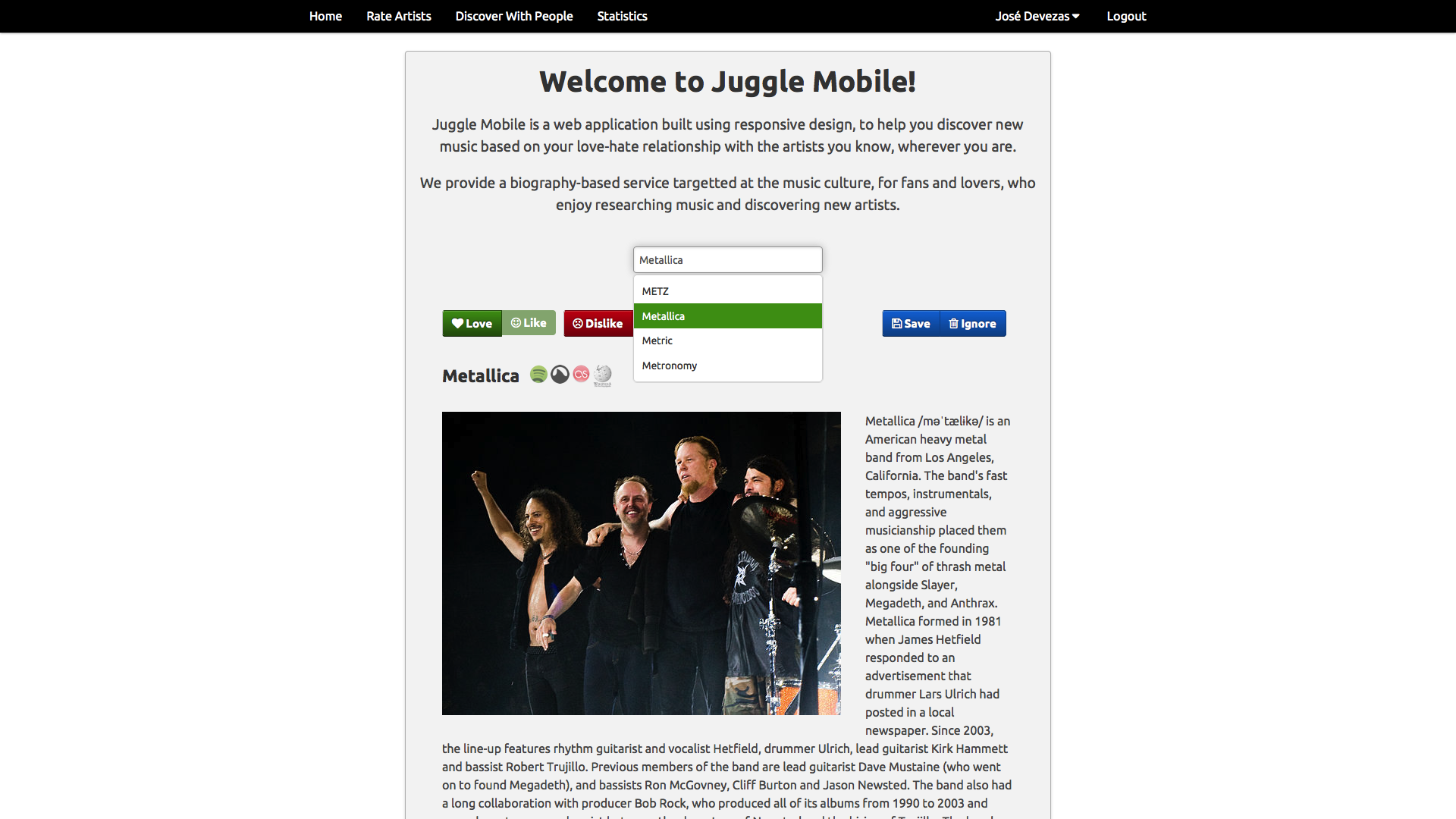
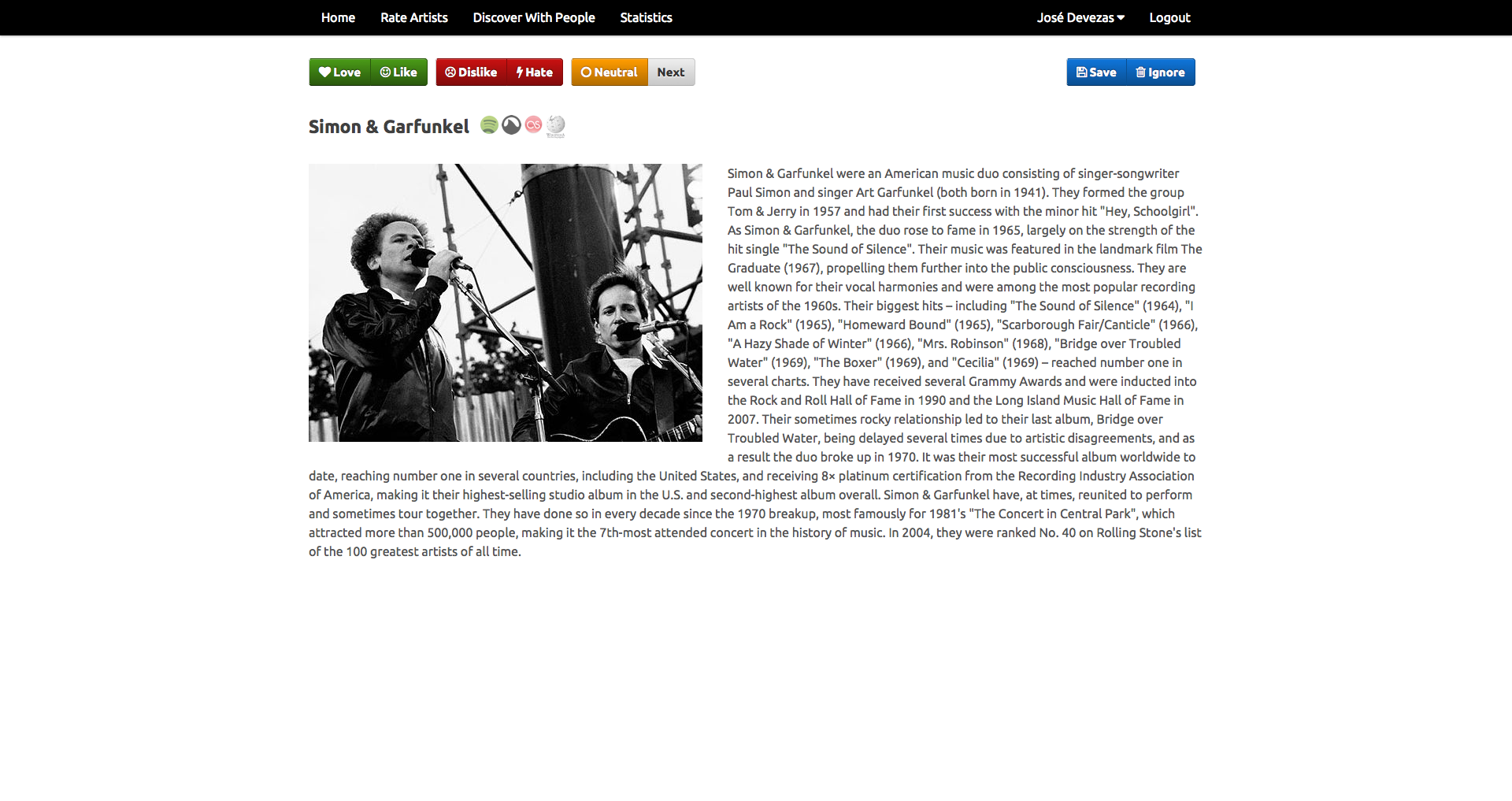
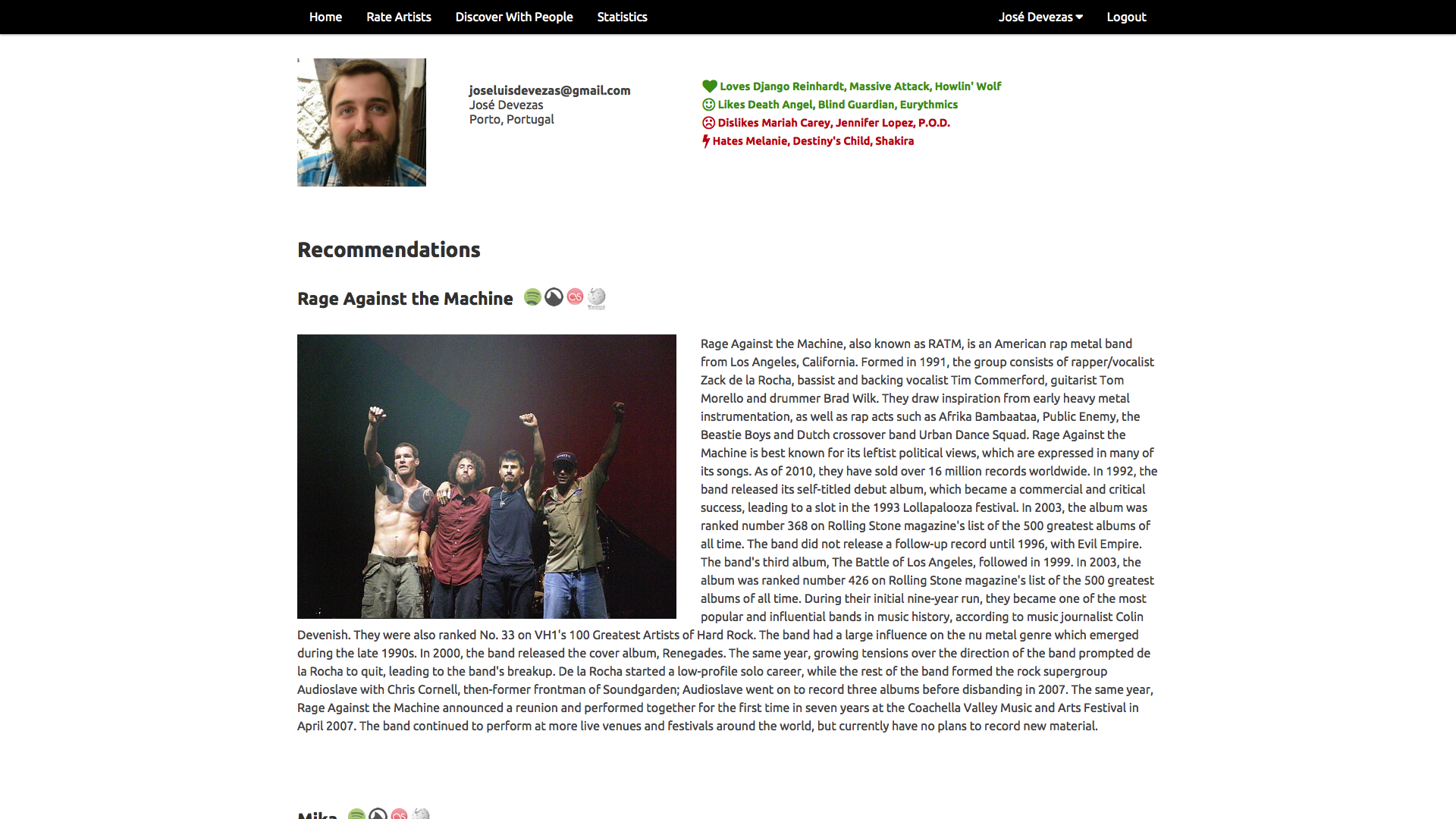
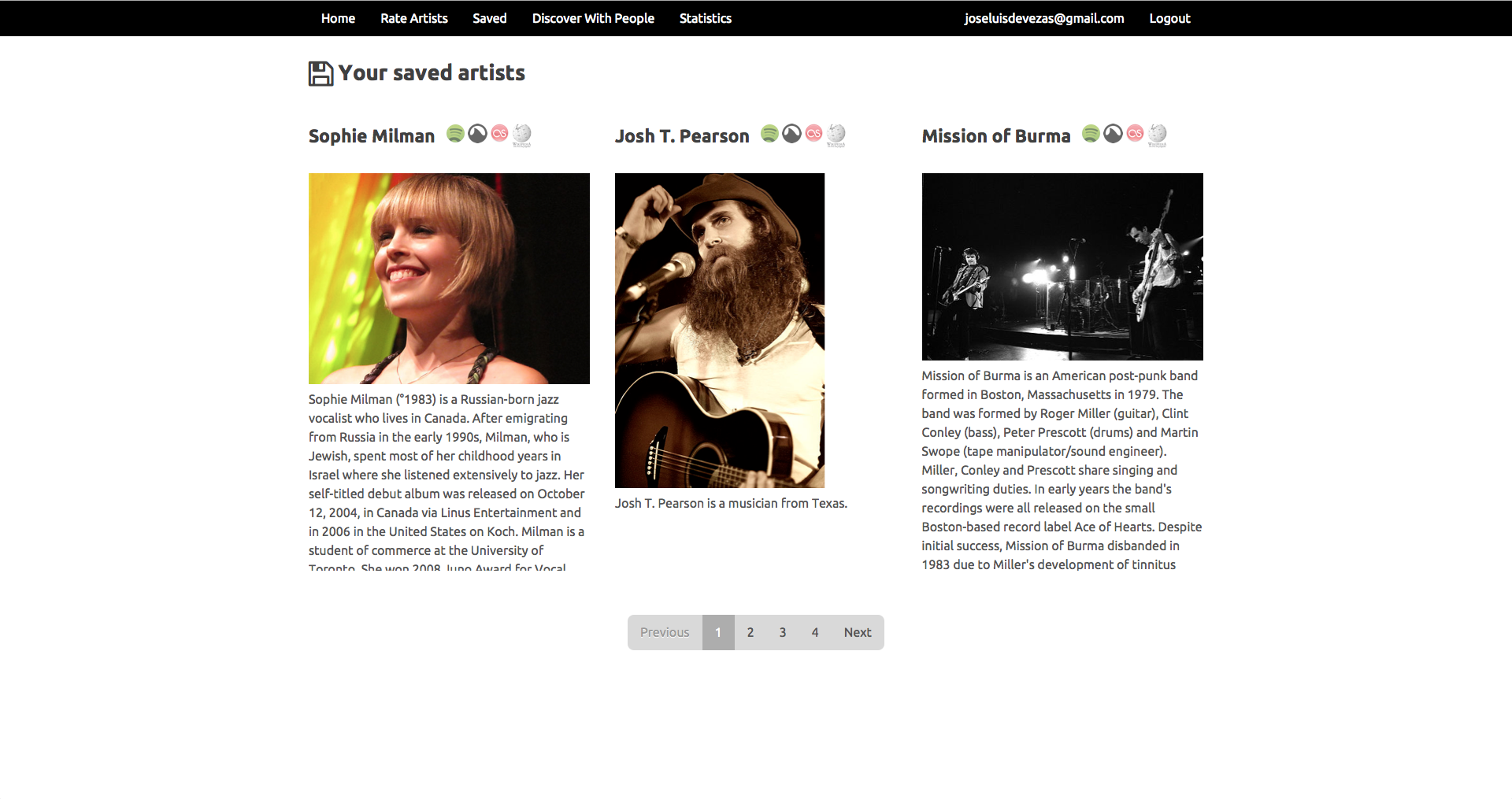
Juggle Mobile⌗
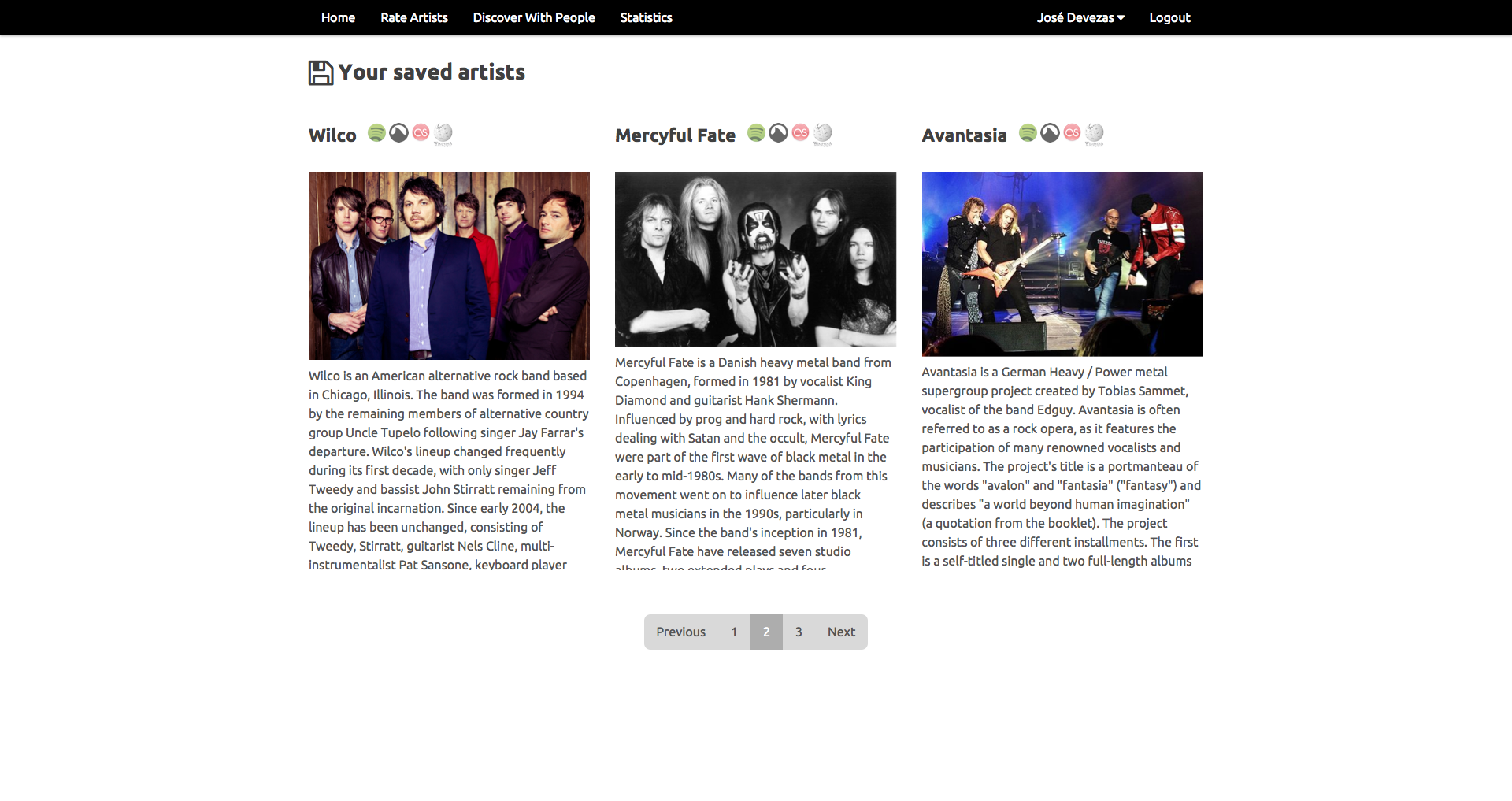
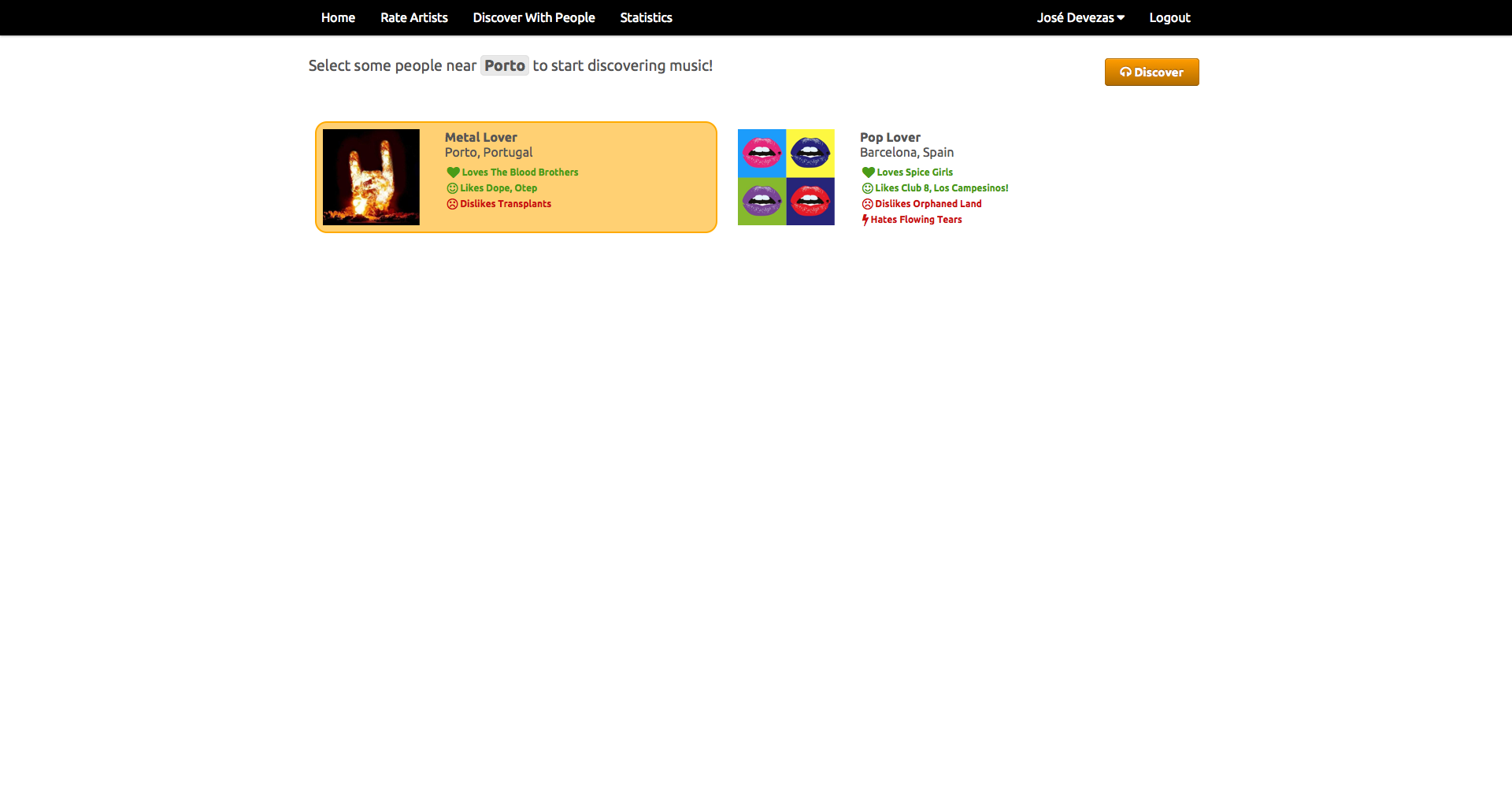
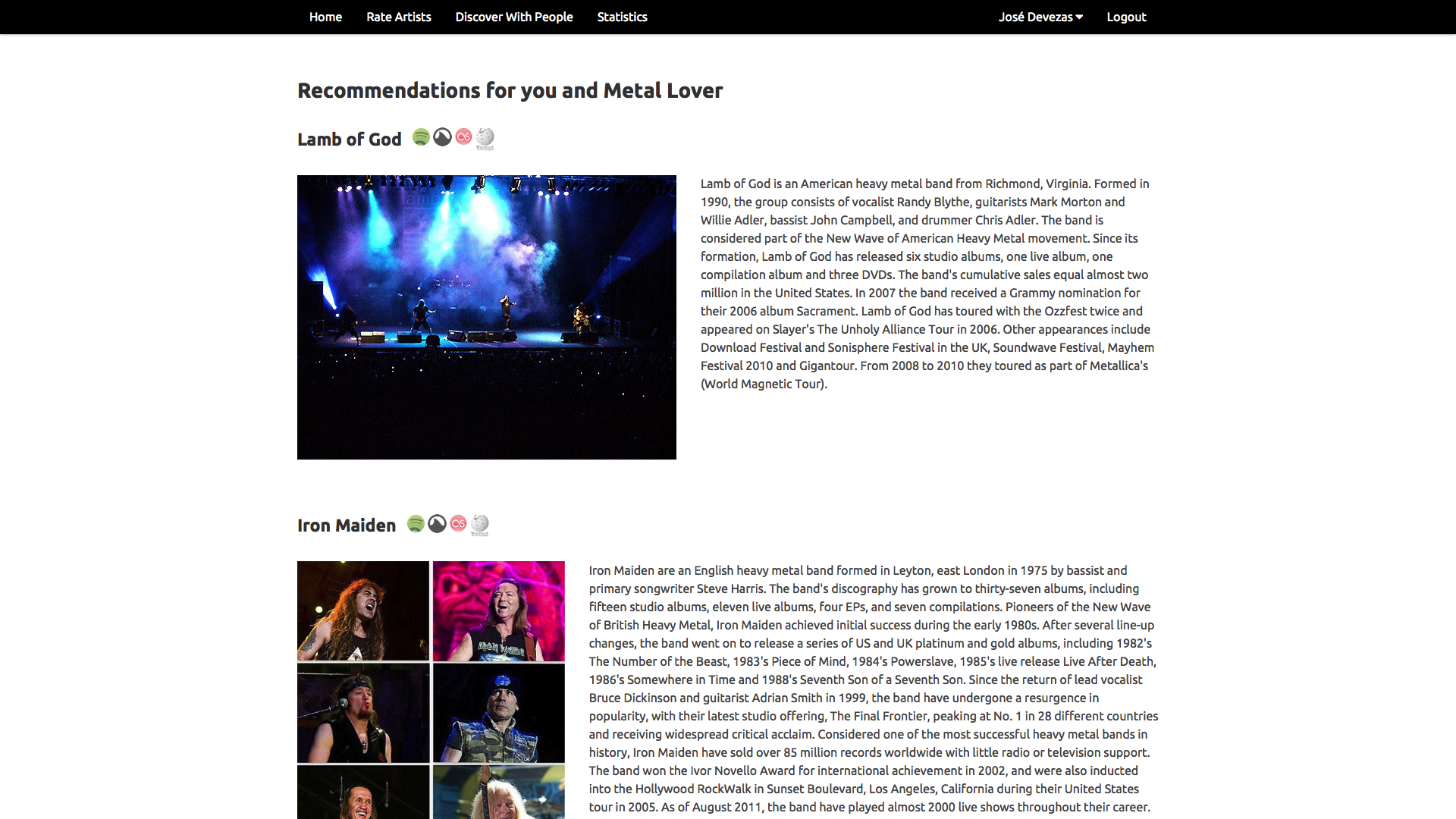
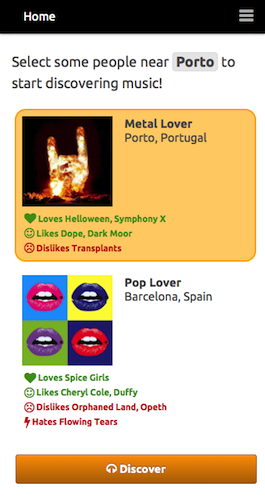
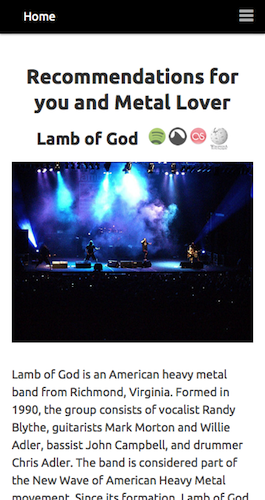
In Juggle Mobile we presented the users with the ability to create an account and fill their taste profiles either based on our random artist rating system, or by importing their existing music information from Facebook or Last.fm. All the data from these different sources was mixed together based on our weighting model and used to provide recommendations to the user or to a group of nearby users.
Our experiments were based on a linear algebra approach, where, instead of a graph, we used a user-items matrix, applying singular value decomposition to build a latent factor model that provided the support for individual and group recommendations. For groups, we proposed a rating aggregation method that ensured an equal chance for every group member to have a relevant influence in the recommendations outcome.



Breadcrumbs⌗
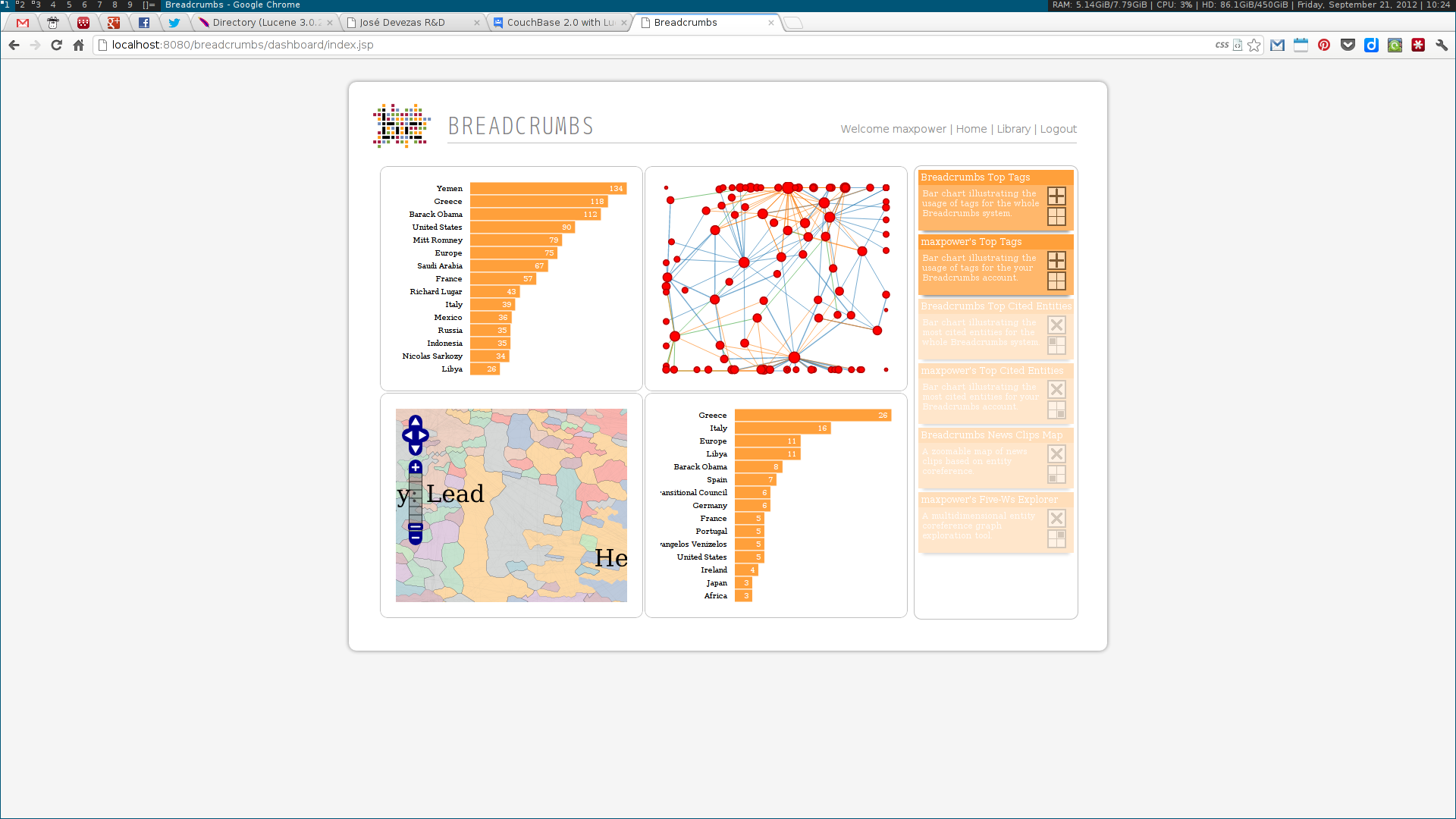
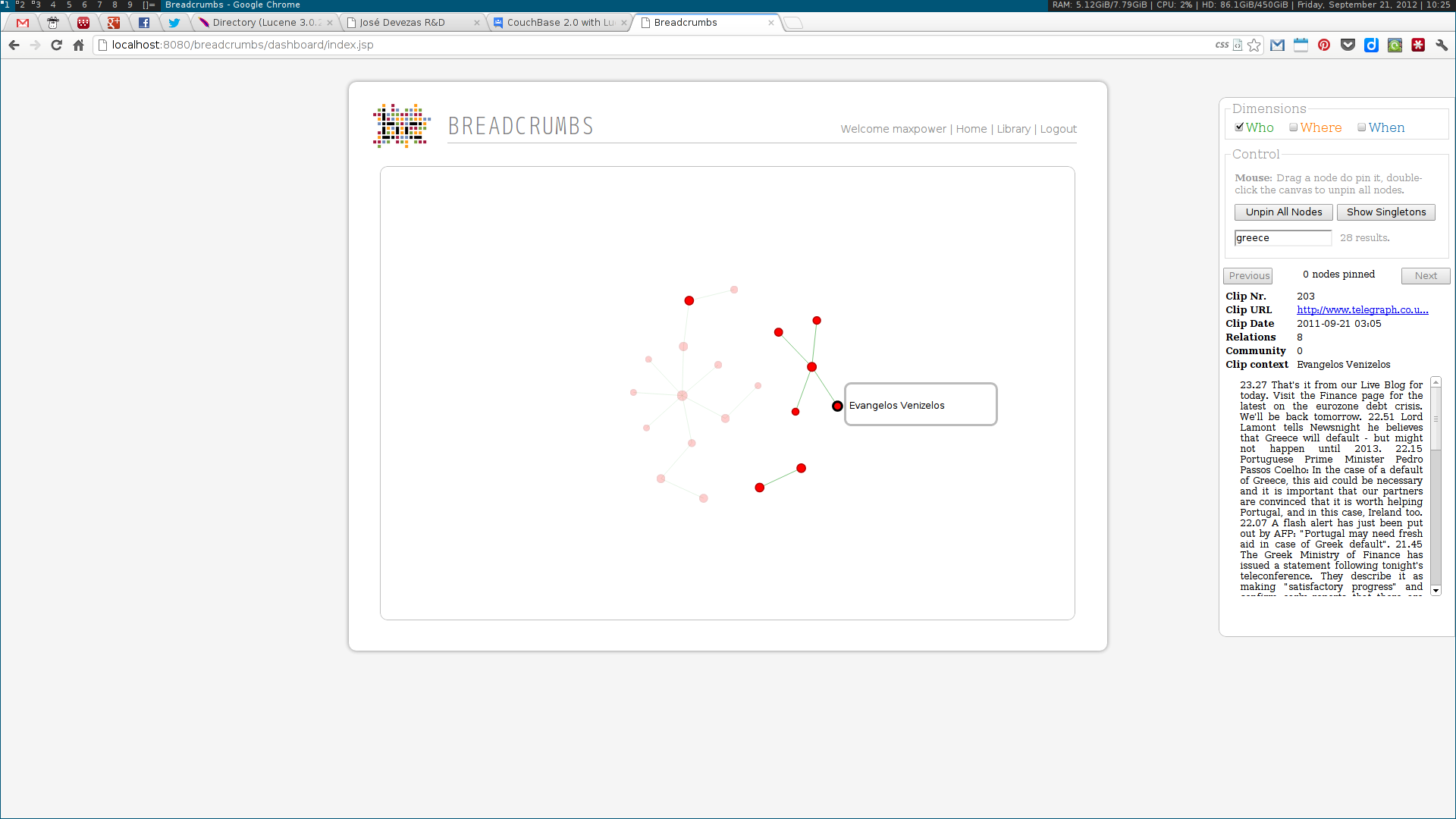
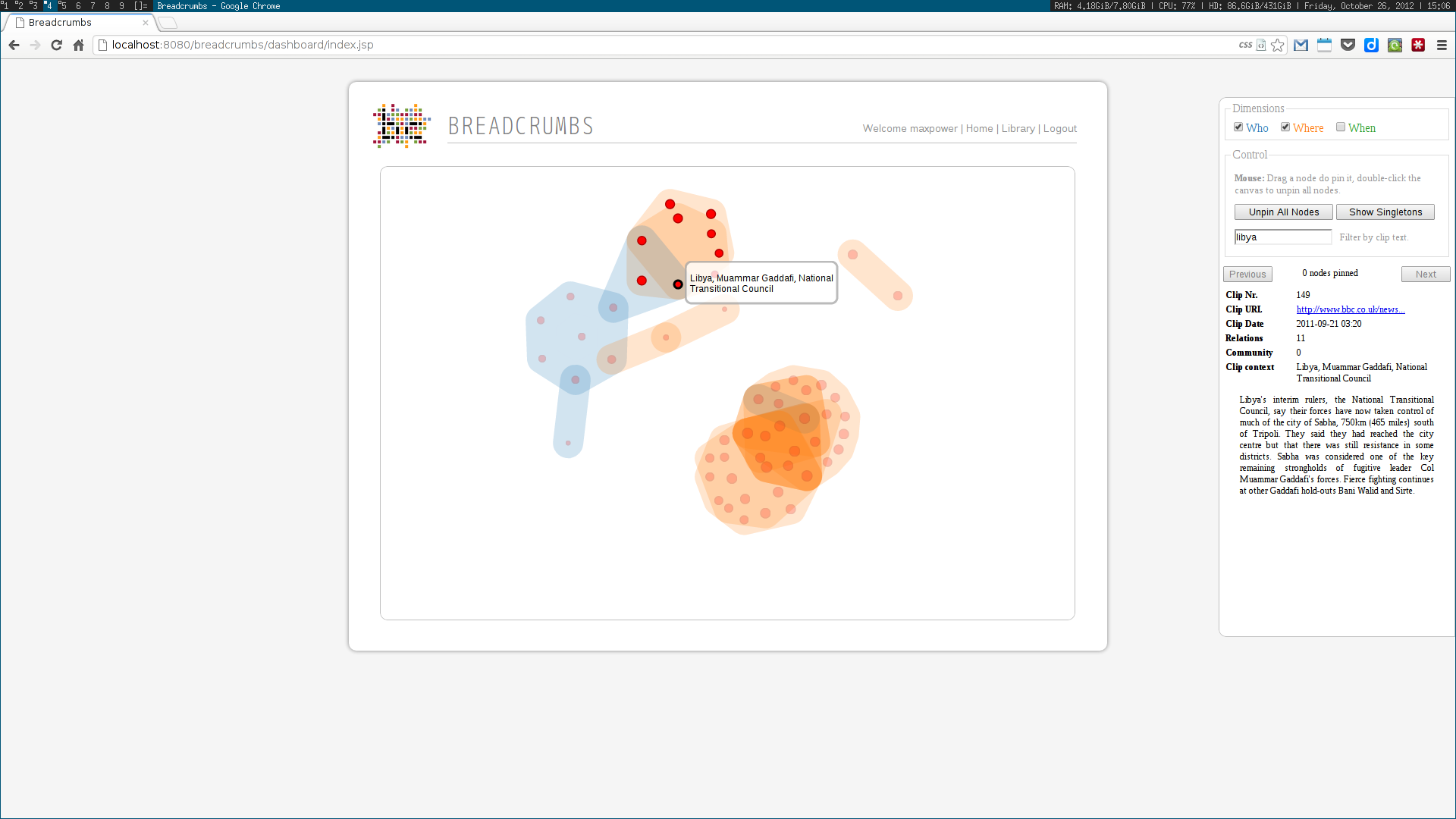
As a Breadcrumbs researcher, I was able to make contributions on several different areas. I implemented a language-independent named entity recognition system based on DBpedia entity lists. This system enabled the identification of three different types of entities — people, places and dates –— tied to three of the five dimensions (the Five-Ws) of journalism: who, where and when. Using this data, a multidimensional entity coreference network was built, connecting news clips that cited the same entity. Next, I implemented the community detection methodologies for multidimensional networks proposed by Tang et al. This included the dimension integration strategies proposed by the authors, based on their unified view of four traditional community detection methodologies. These algorithms were also implemented in the system, along with the Louvain method, one of the state of the art algorithms for community detection.
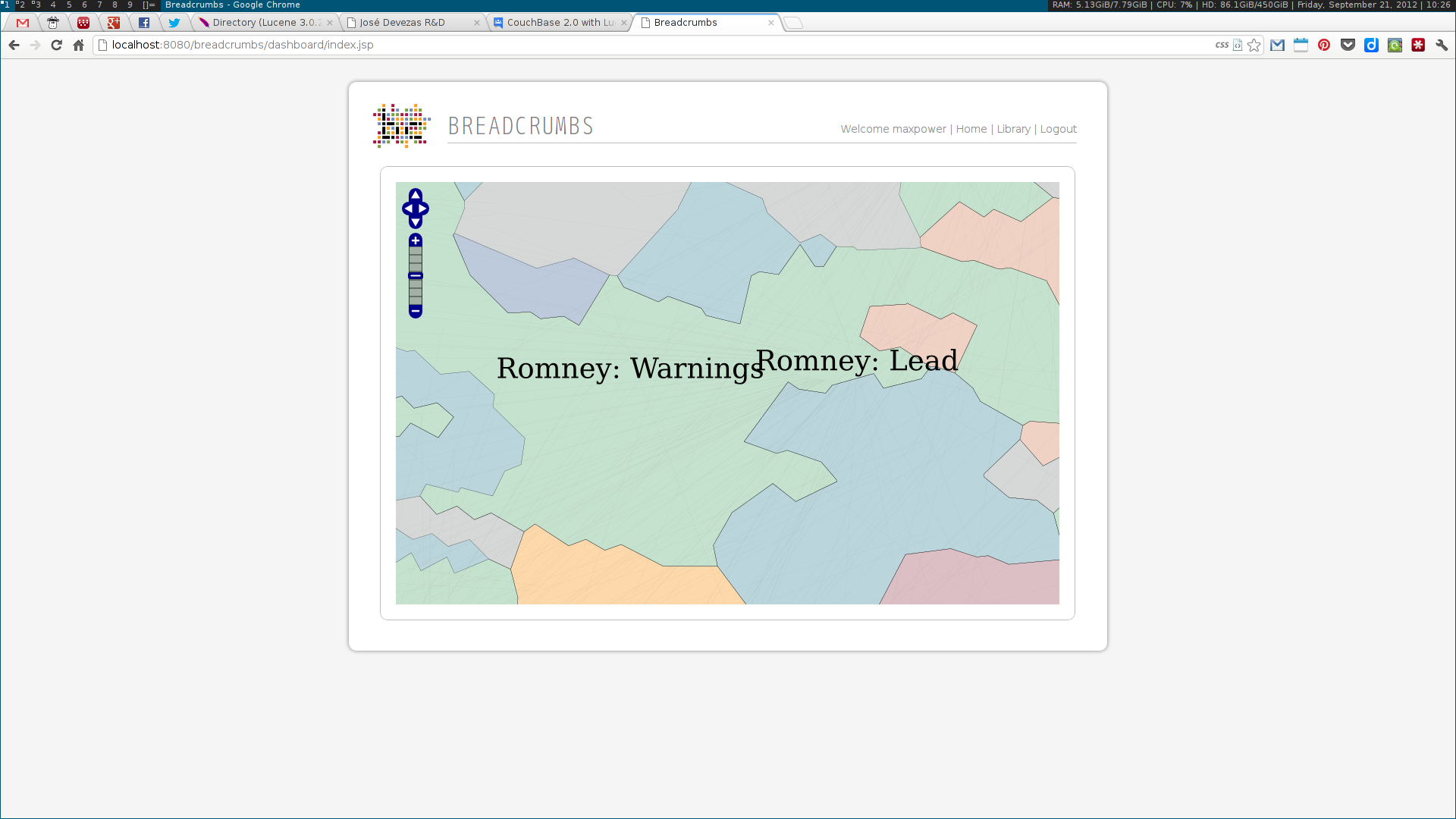
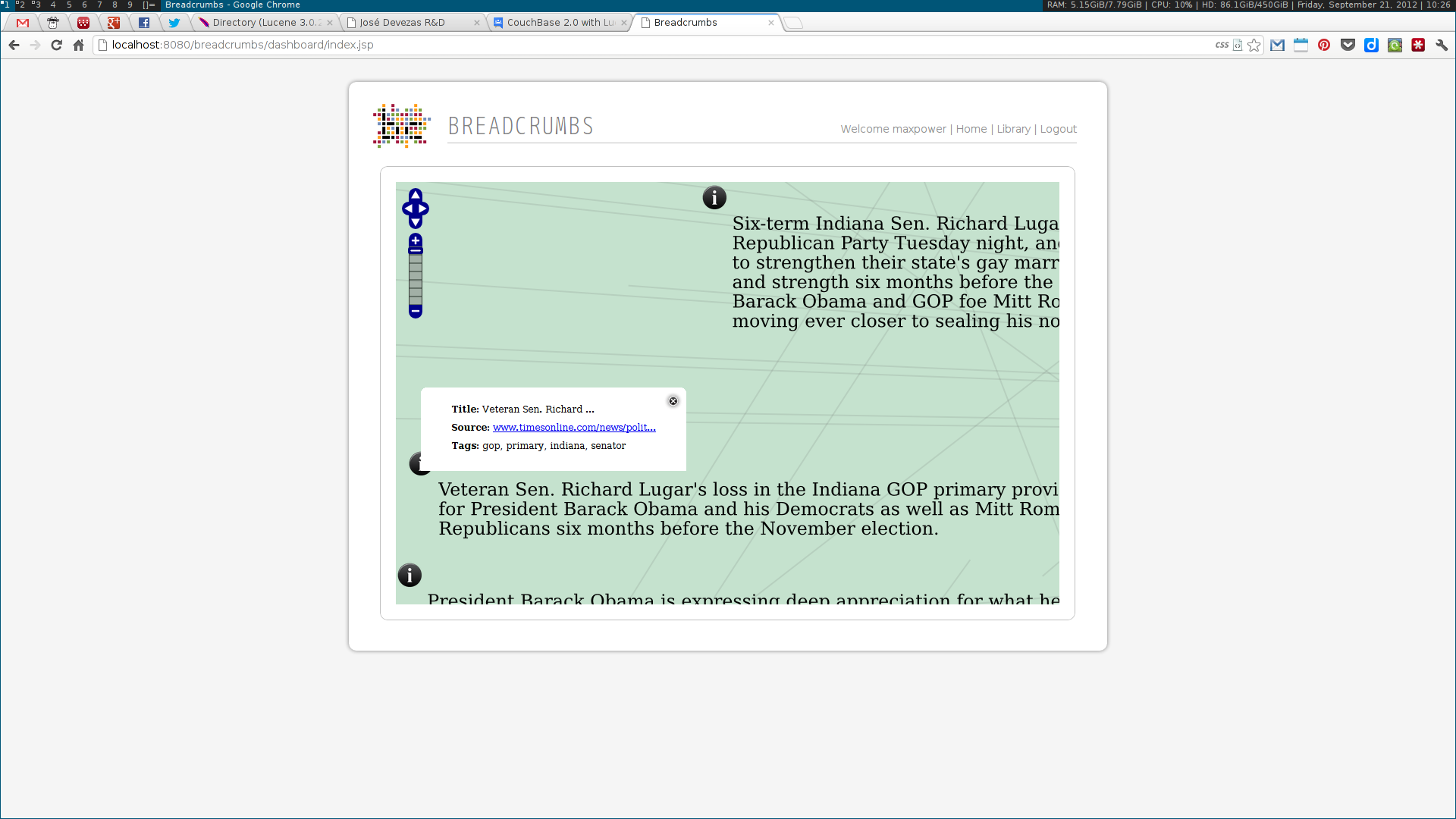
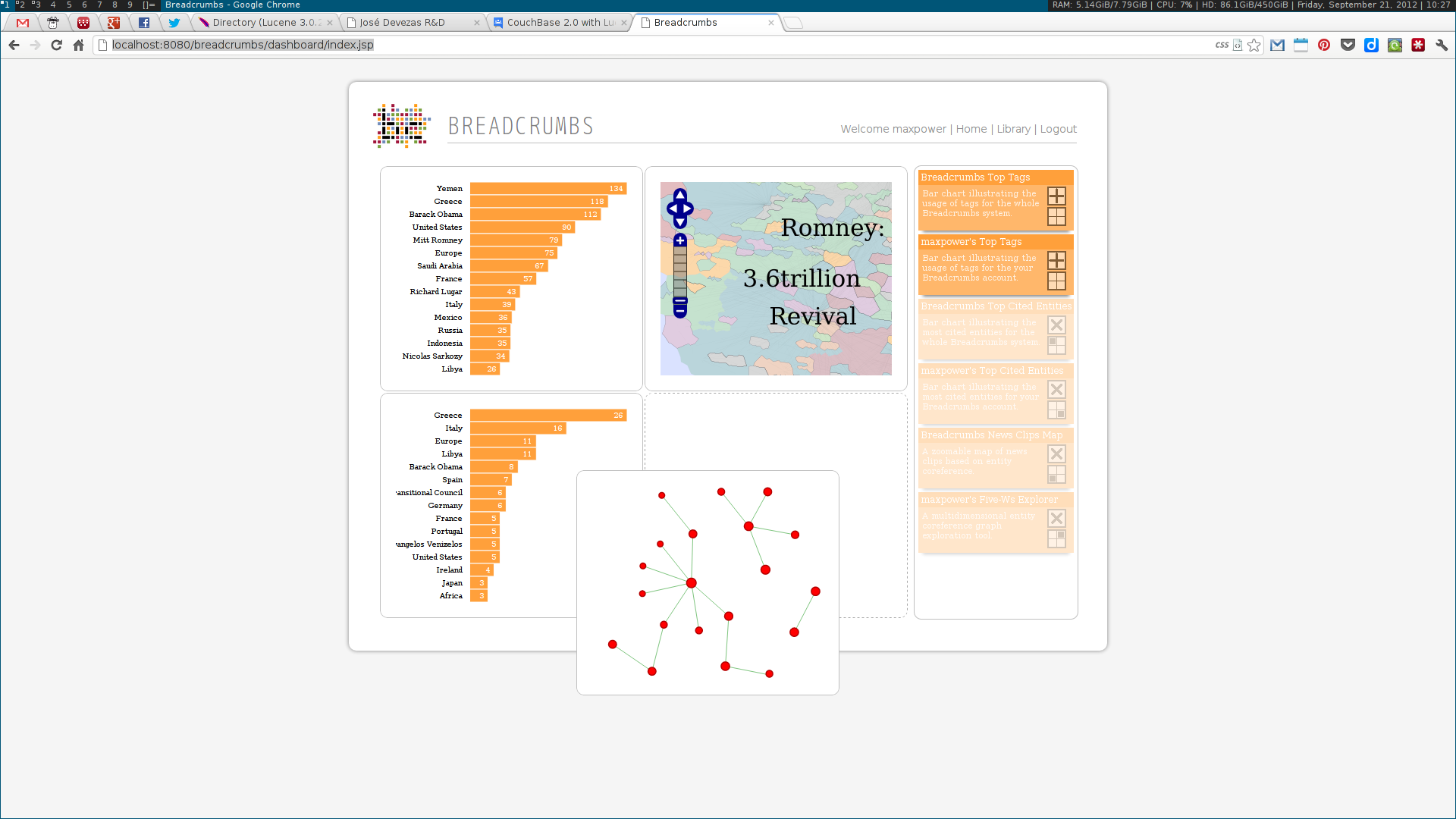
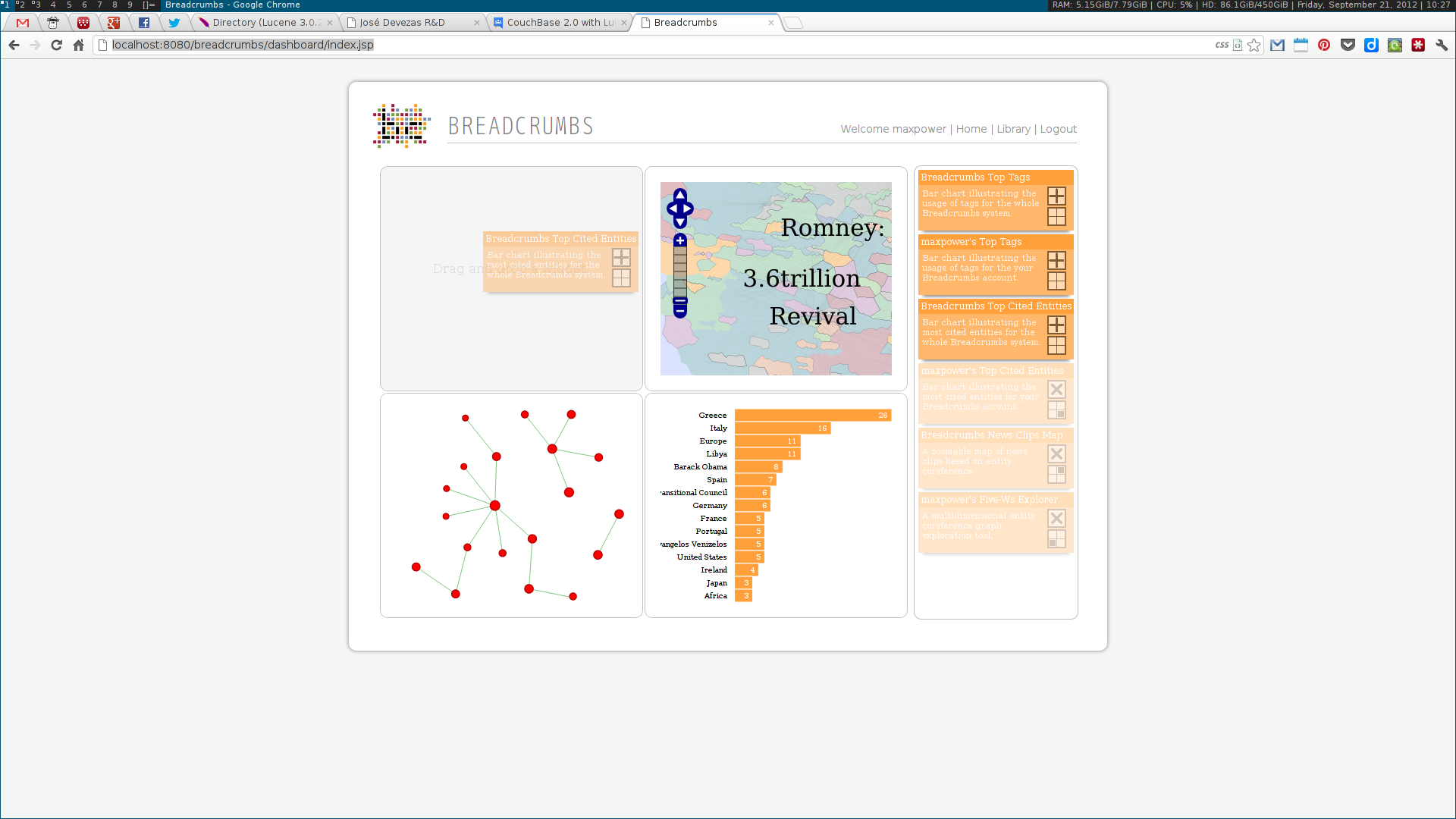
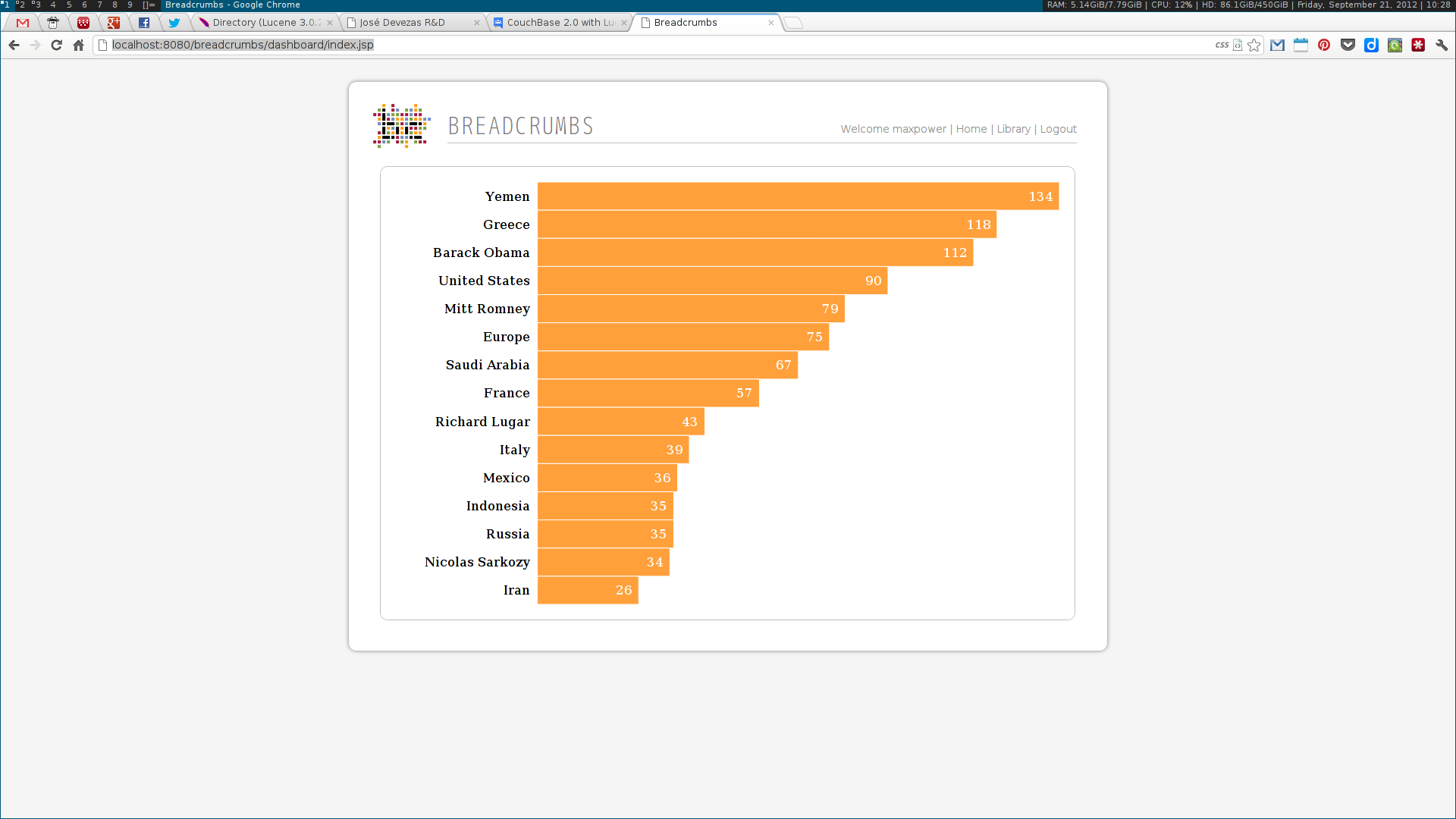
Next, two visualization tools were developed to display and explore the acquired data. The first was analogous to a map, where communities were visualized as countries resulting of the aggregation of a node population. The second enabled the exploration of the multidimensional network based on the three identified dimensions: who, where and when. Some simple chart visualizations were created to display statistics about the top user and system tags and entities.
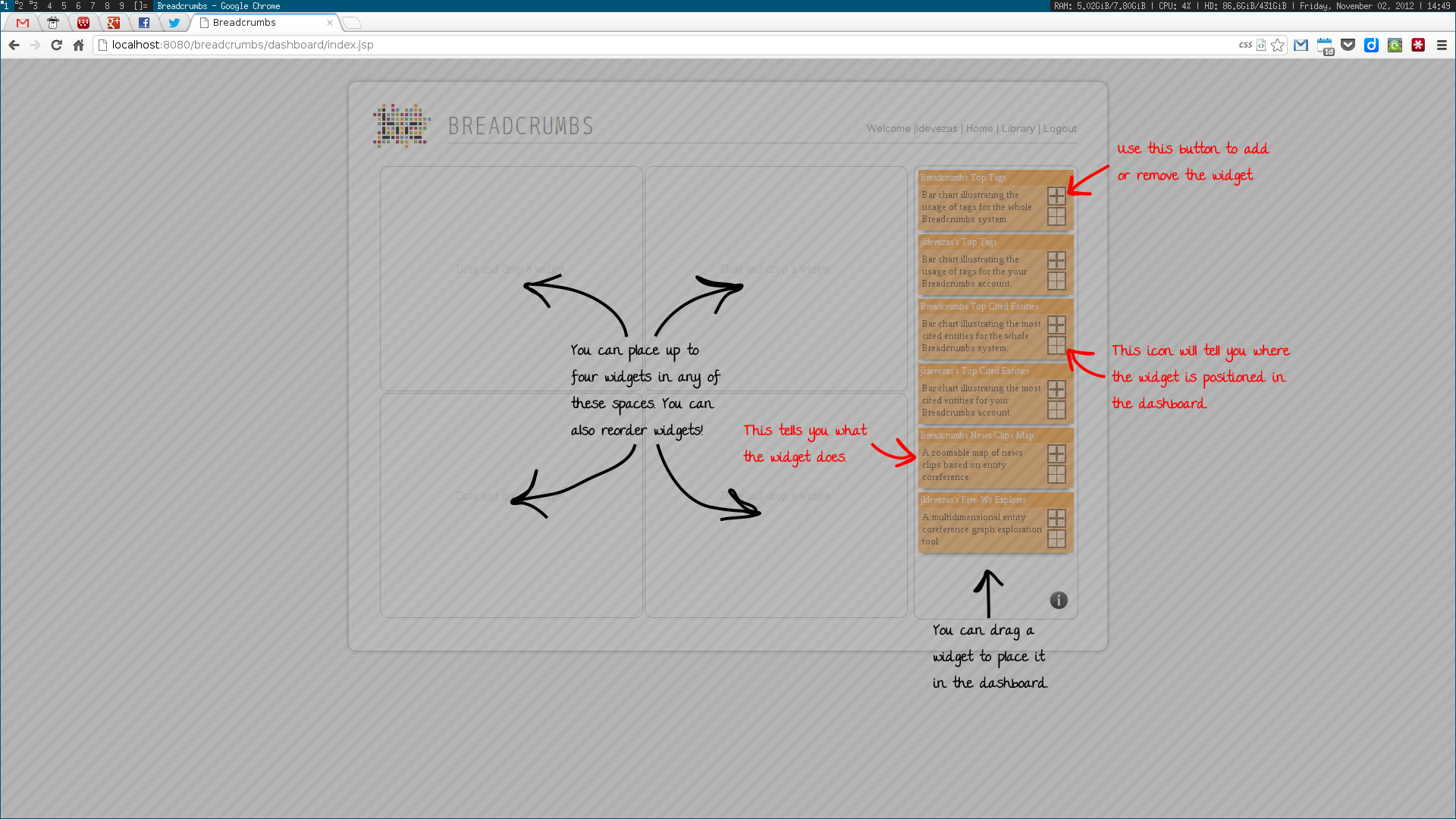
We used a topic model, based on Latent Dirichlet Allocation, to suggest titles for each collection of news clips; a simplistic event detection system was also created, in order to find relevant peaks of activity in a time series of entity frequencies. Some other trivial systems, such as an administration panel, capable of scheduling tasks, and a widget dashboard were also implemented.
These algorithms were all developed using a web services architecture, communicating using either XML or JSON. Several scientific papers were published as the results of the described research. Below are some screenshots of the Breadcrumbs modules I contributed to in some way.
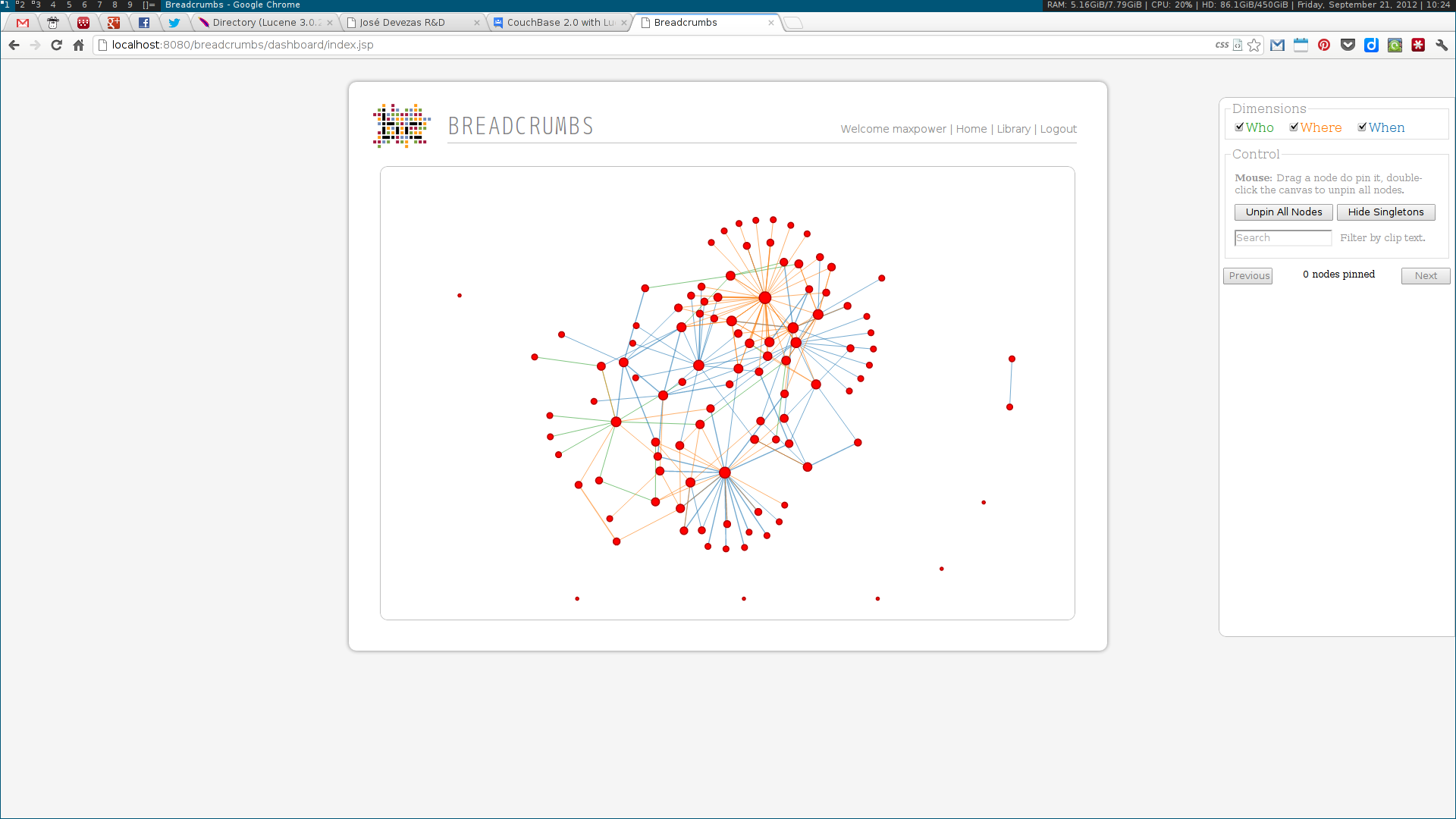
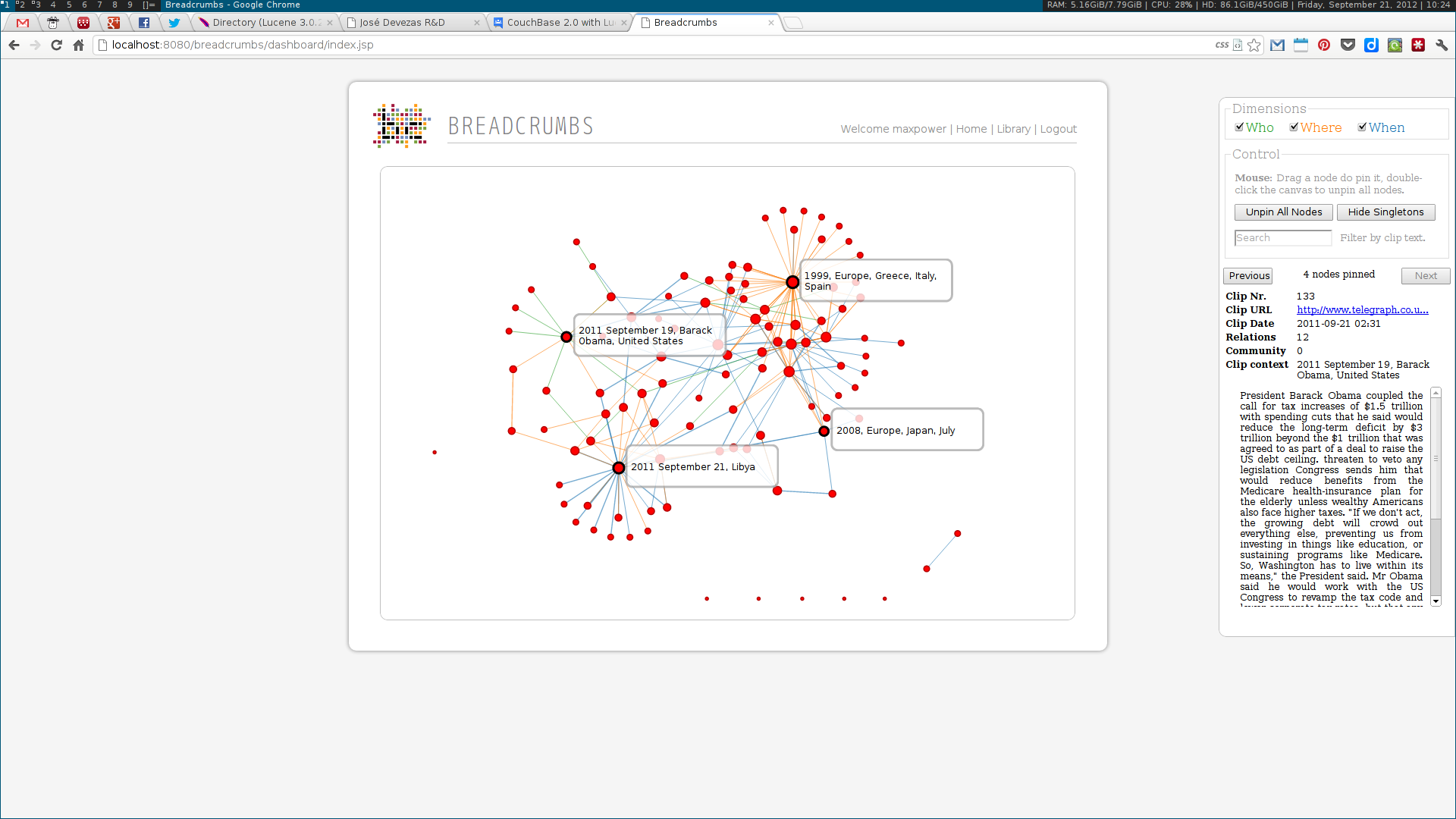
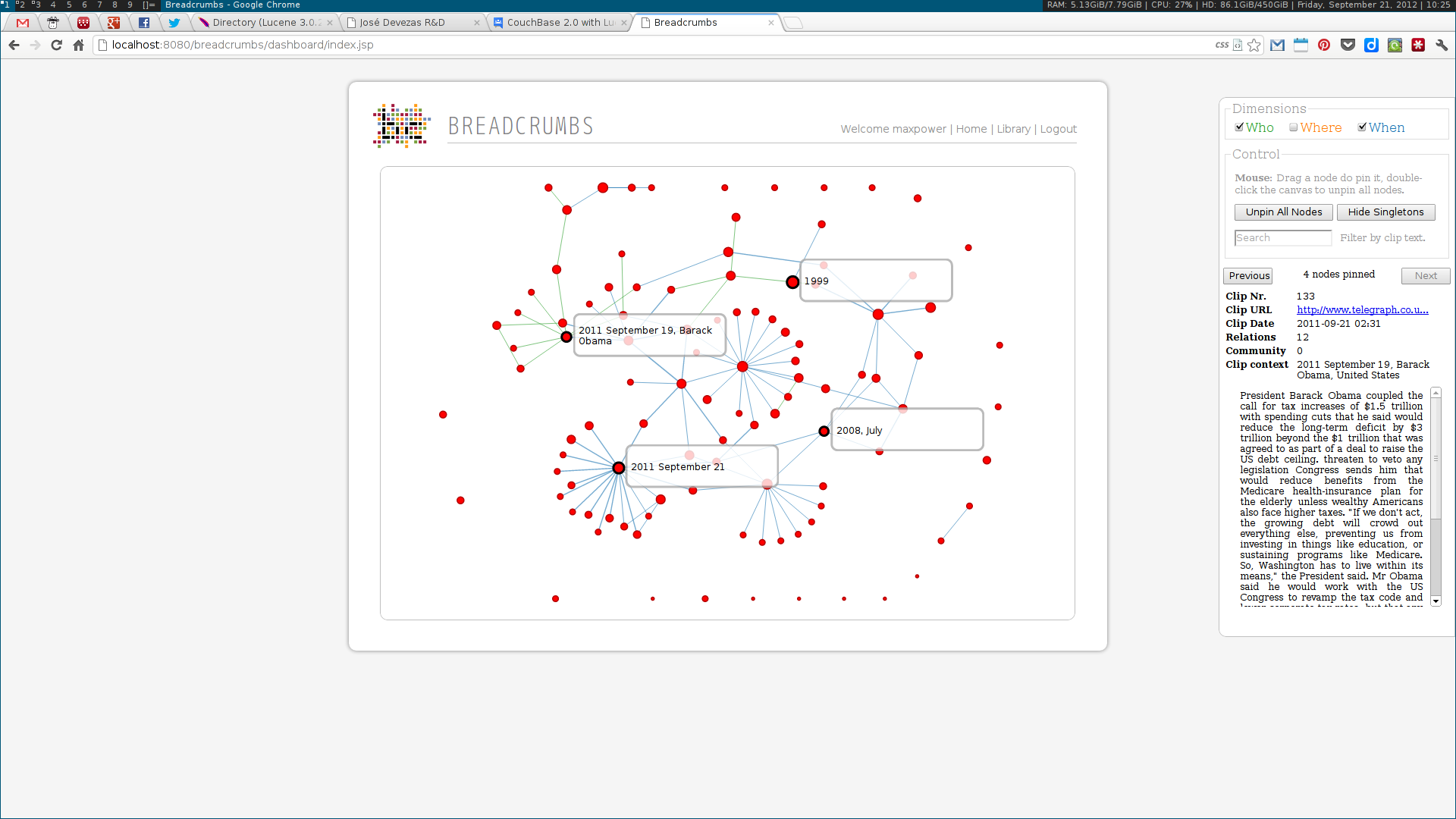
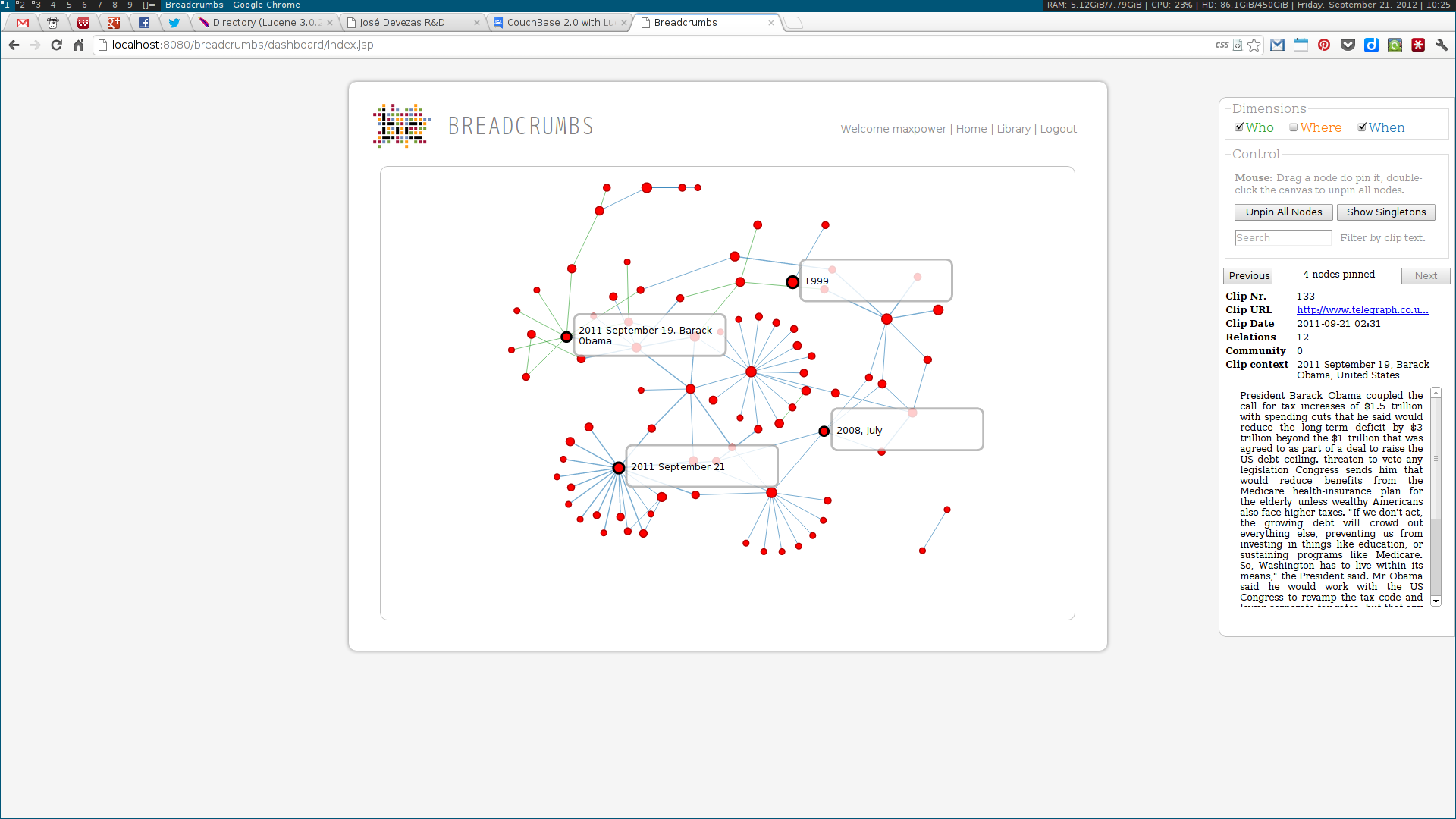
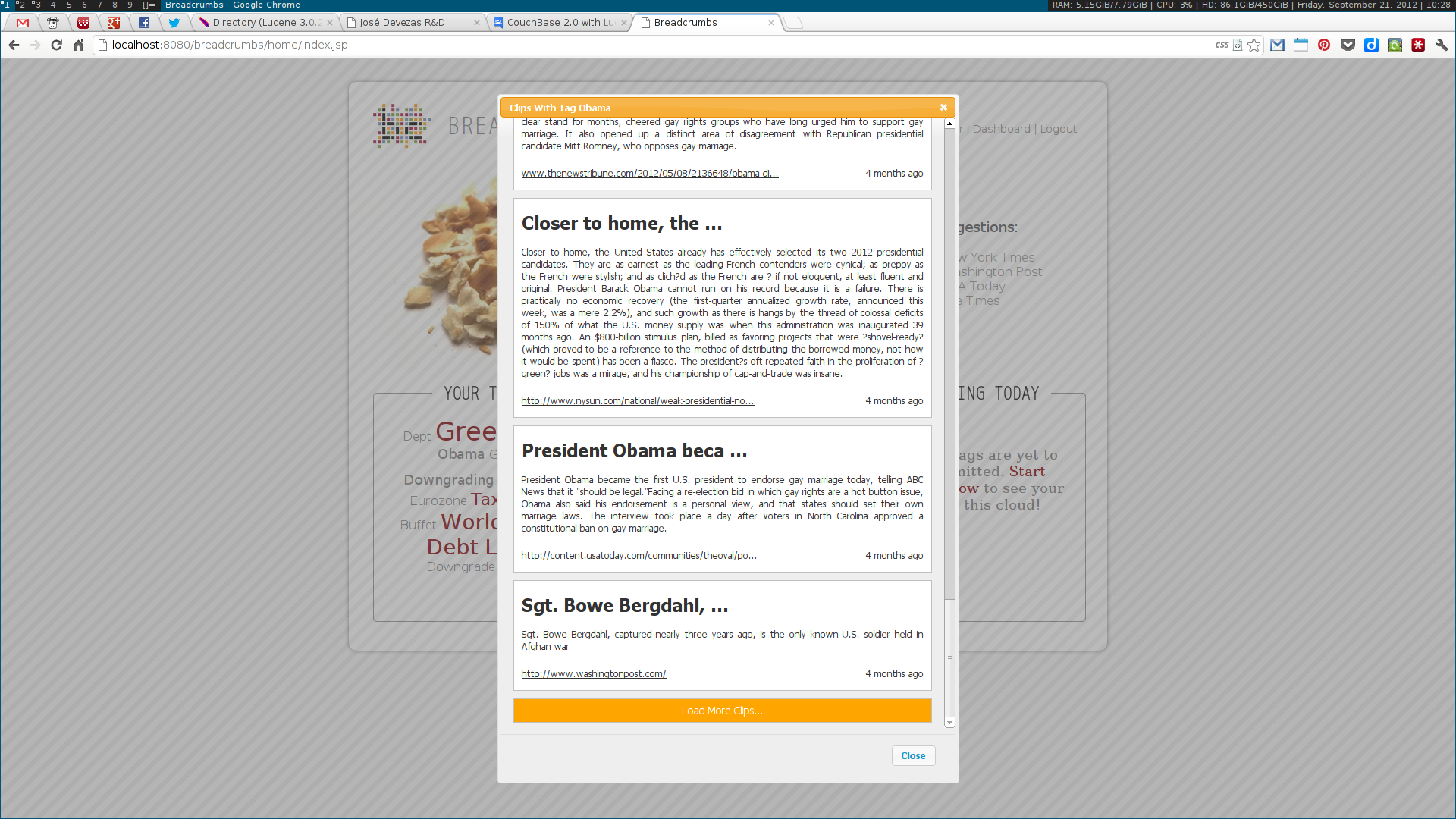
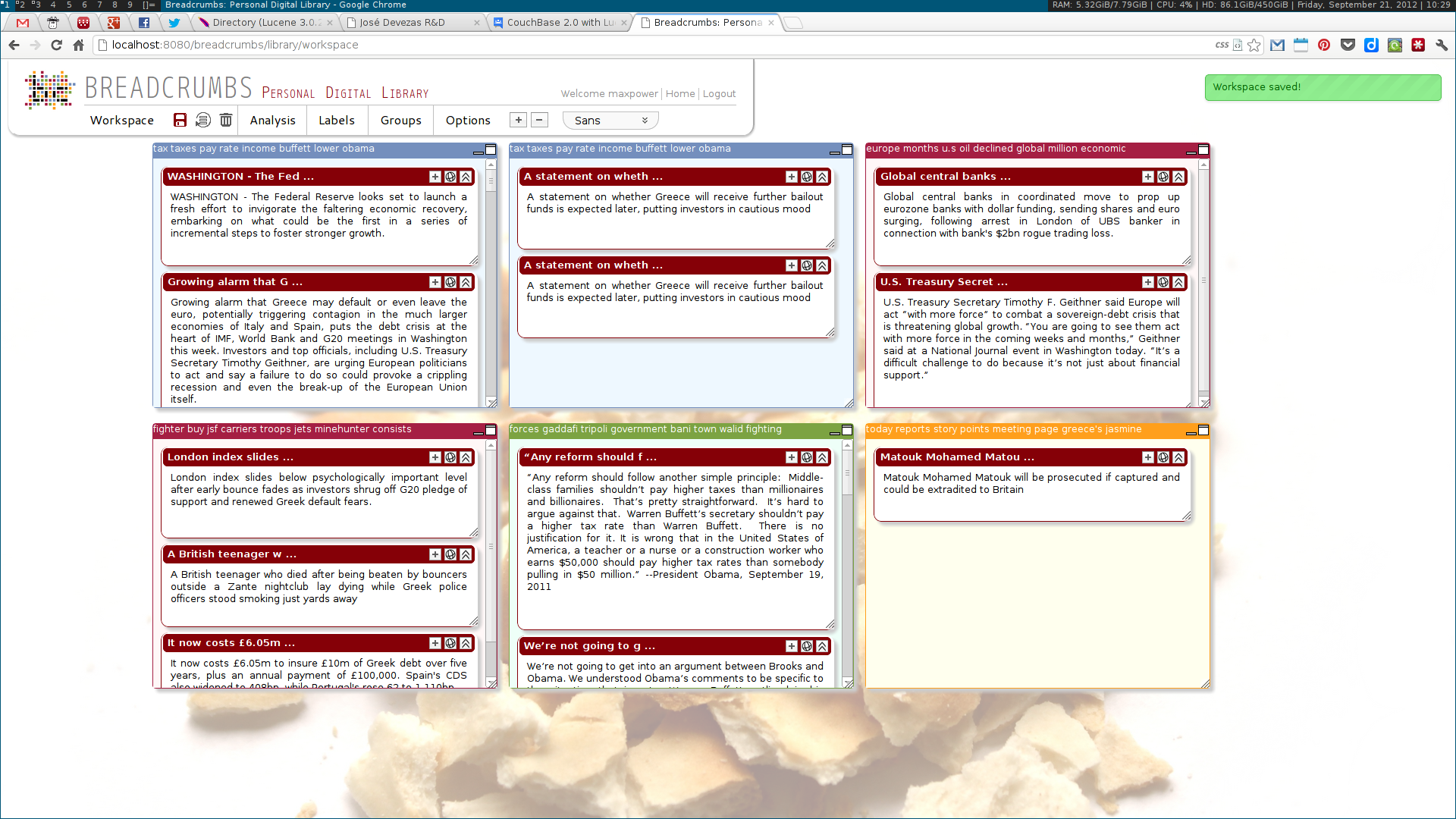
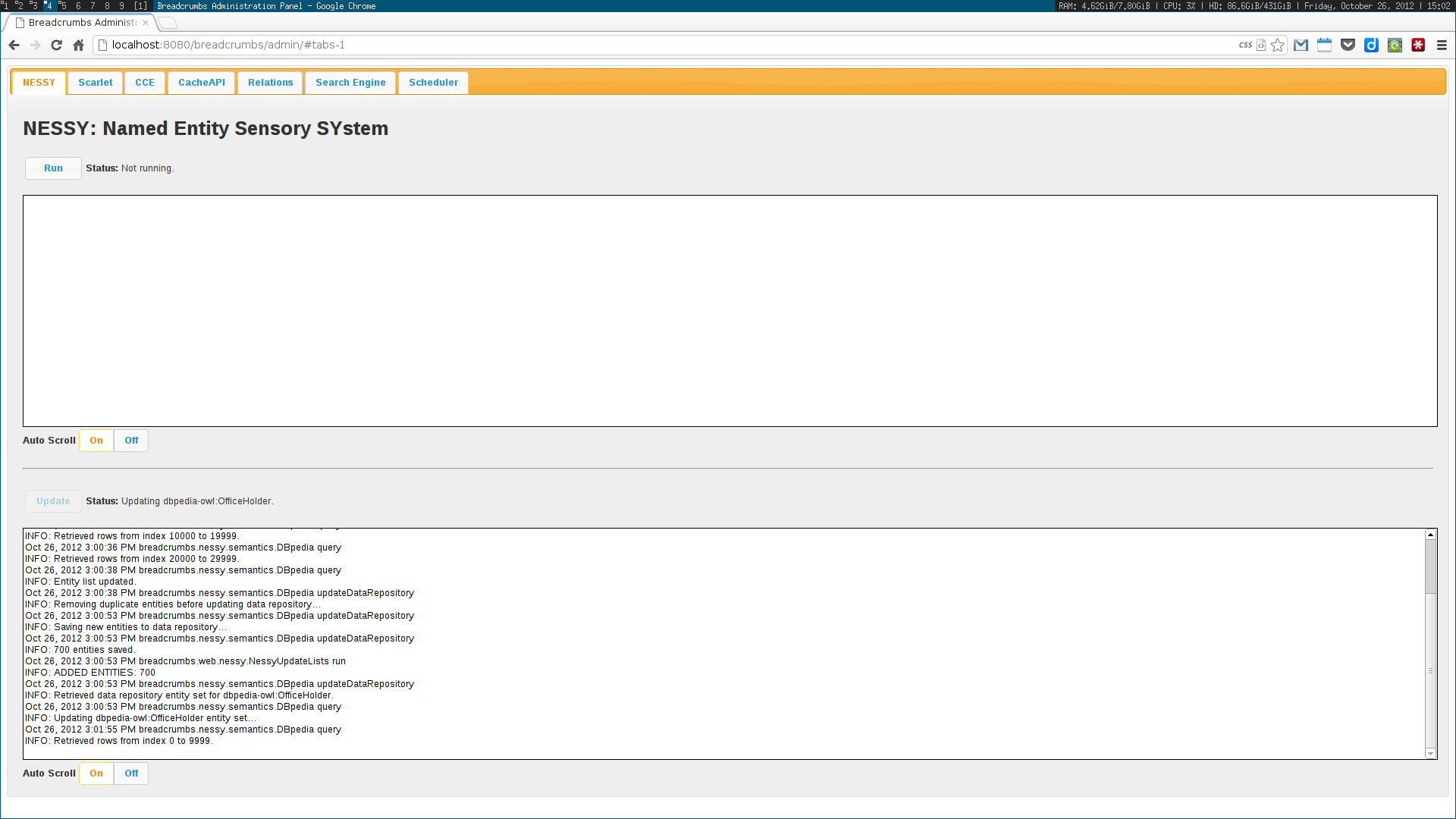
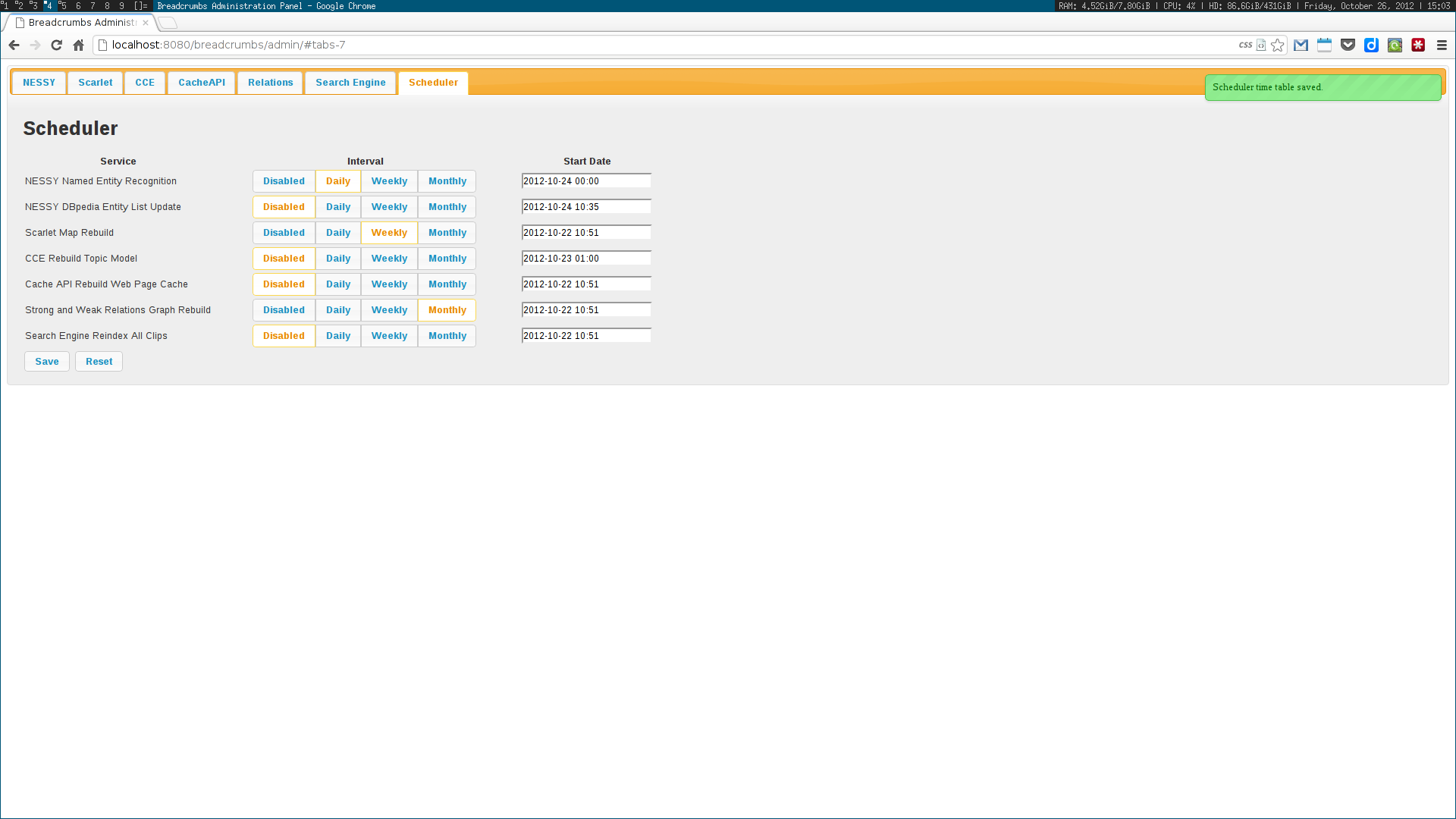
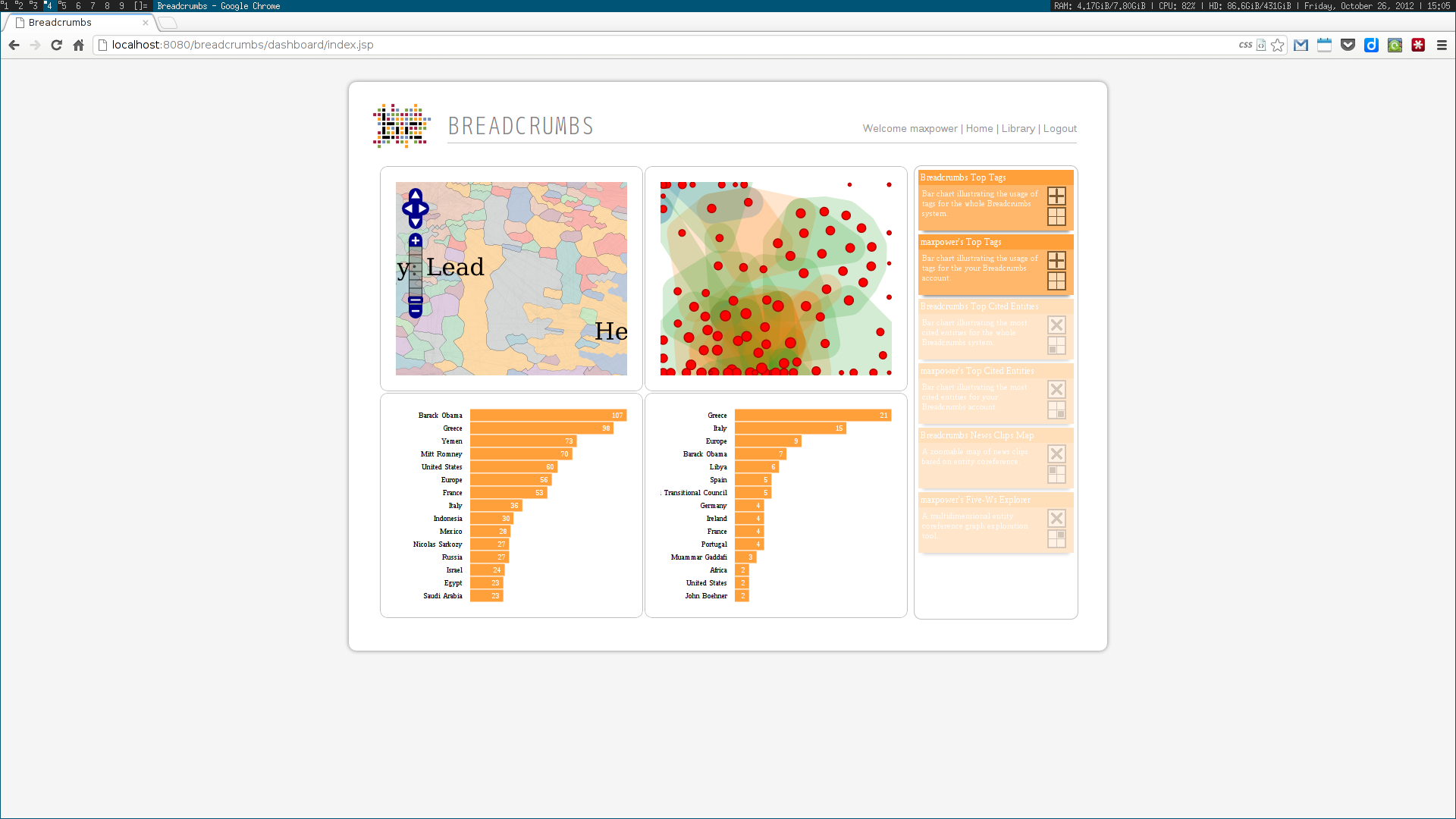
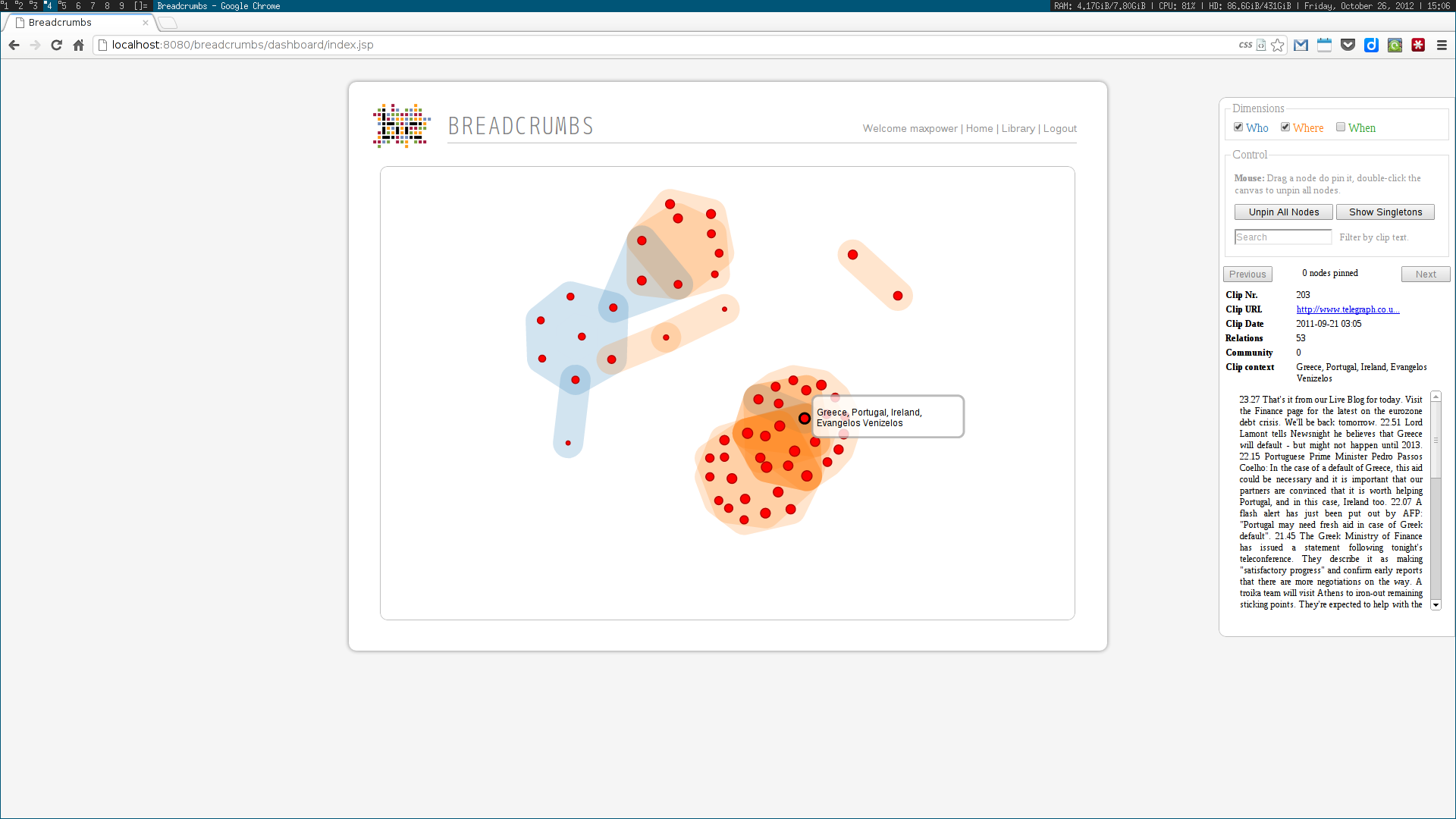
Ciclope⌗
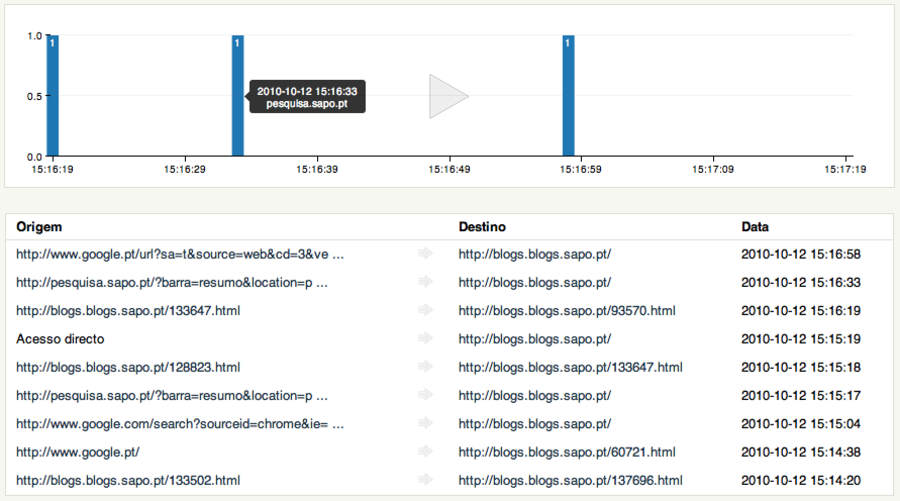
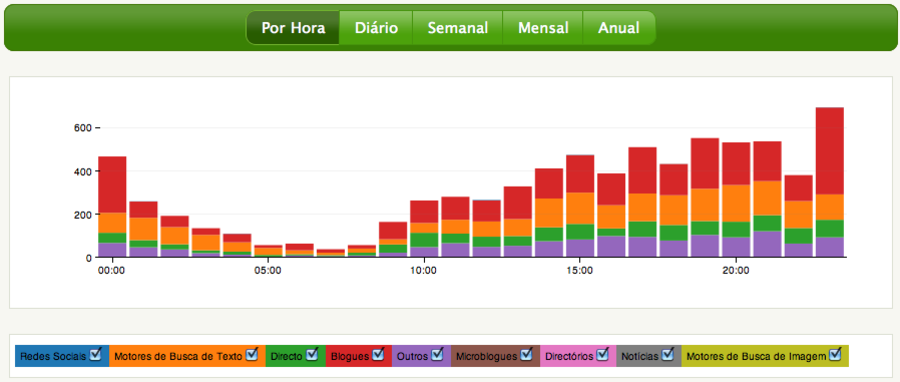
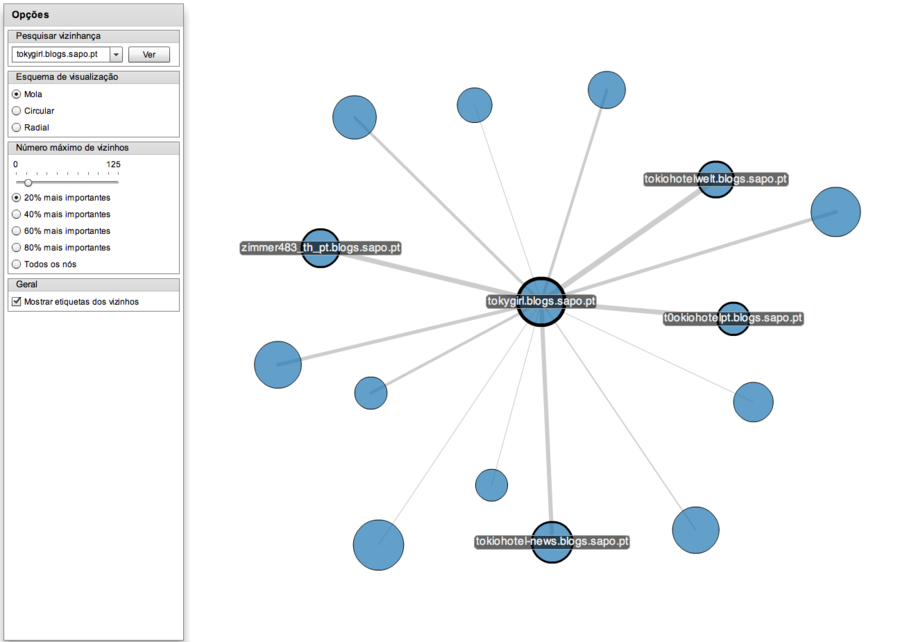
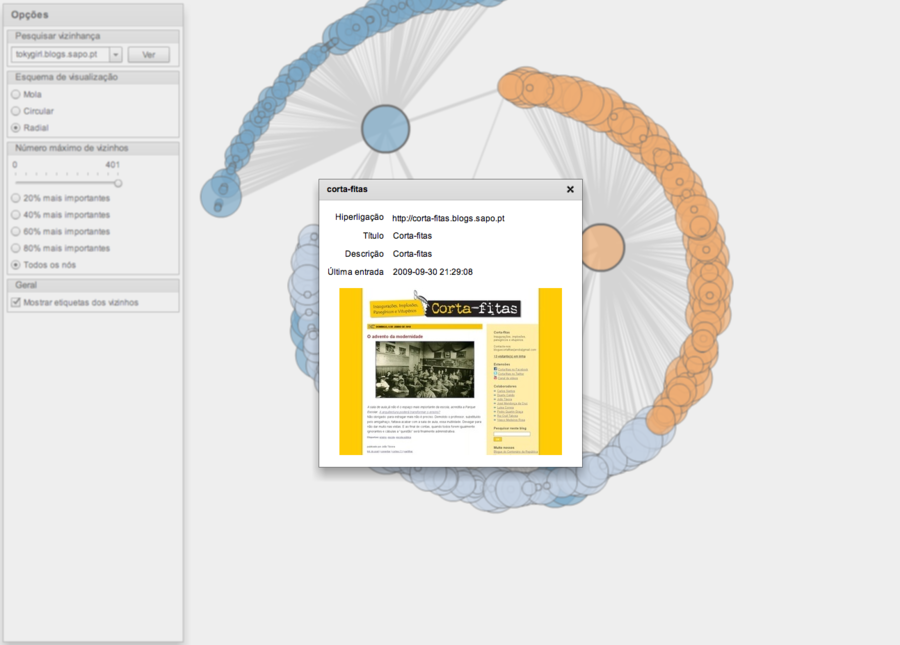
One of my first projects was Ciclope, a real time data visualization project aimed at gathering information from SAPO Blogs clickstream and displaying it in a useful way, allowing the blog owner to have an understanding of how the traffic flow of his or her blog behaved.
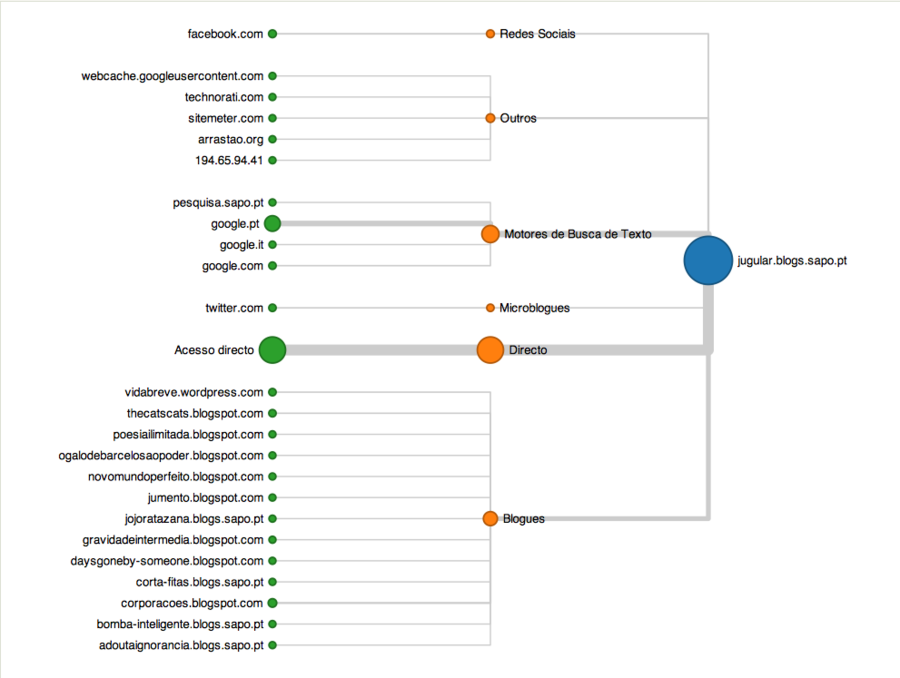
Among other widgets, we developed two main visualizations: a real time bar chart that displayed the number of visits per second along with a table showing traffic origin and destination; and a custom flow tree to visualize and quantify aggregated traffic sources for a given blog.